This article suggests that the current atmospheric CO2 level is already triggering amplifying feedbacks from the Earth system and therefore, in themselves, efforts at reduction in atmospheric CO2-emission are no longer sufficient to prevent further global warming. For this reason, along with sharp reductions in carbon emissions, efforts need to be undertaken in an attempt to reduce atmospheric CO2 levels from their current level of near-400 ppm to well below 350 ppm. NASA-applied outer space-shade technology may buy time for such planetary defense effort.
The scale and rate of modern climate change have been greatly underestimated. The release to date of a total of over 560 billion ton of carbon through emissions from industrial and transport sources, land clearing and fires, has raised CO2 levels from about 280 parts per million (ppm) in pre-industrial periods to 397-400 ppm and near 470 ppm CO2-equivalent (a value which includes the CO2-equivalent effect of methane), reaching a current CO2 growth rate of about 2 ppm per year
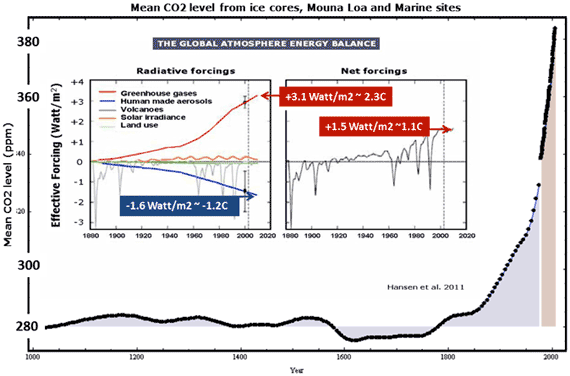
Figure 1: Part A. Mean CO2 level from ice cores, Mouna Loa observatory and marine sites; Part B (inset). Climate forcing 1880 – 2003. Aerosol forcing includes all aerosol effects, including indirect effects on clouds and snow albedo. GHGs include ozone (O3) and stratospheric H2O, in addition to well-mixed greenhouse gases.
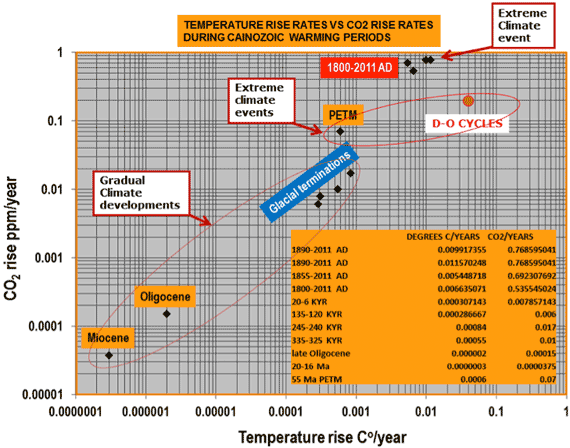
Figure 2: Relations between CO2 rise rates and mean global temperature rise rates during warming periods, including the Paleocene-Eocene Thermal Maximum, Oligocene, Miocene, glacial terminations, Dansgaard-Oeschger cycles and the post-1750 period.
These developments are shifting the Earth’s climate toward Pliocene-like (5.2 – 2.6 million years-ago; mean global temperatures of +2-3oC above pre-industrial temperatures) and possibly toward mid-Miocene-like (approximately 16 million years-ago; mean global temperatures +4oC above pre-industrial temperatures) conditions within a few centuries?a geological blink of an eye.
The current CO2 level generates amplifying feedbacks, including the reduced capacity of warming water to absorb CO2 from the atmosphere, CO2 released from fires, droughts, loss of vegetation cover, disintegration of methane released from bogs, permafrost and methane-bearing ice particles and methane-water molecules.
With CO2 atmospheric residence times in the order of thousands to tens of thousands years, protracted reduction in emissions, either flowing from human decision or due to reduced economic activity in an environmentally stressed world, may no longer be sufficient to arrest the feedbacks.
Four of the large mass extinction of species events in the history of Earth (end-Devonian, Permian-Triassic, end-Triassic, K-T boundary) have been associated with rapid perturbations of the carbon, oxygen and sulphur cycles, on which the biosphere depends, at rates to which species could not adapt.
Since the 18th century, and in particular since about 1975, the Earth system has been shifting away from Holocene (approximately 10,000 years to the pre-industrial time) conditions, which allowed agriculture, previously hindered by instabilities in the climate and by extreme weather events. The shift is most clearly manifested by the loss of polar ice. Sea level rises have been accelerating, with a total of more than 20 cm since 1880 and about 6 cm since 1990.
For temperature rise of 2.3oC, to which the climate is committed if sulphur aerosol emission discontinues (see Figure 1), sea levels would reach Pliocene-like levels of 25 meters plus or minus 12 meters, with lag effects due to ice sheet hysteresis (system inertia).
With global atmospheric CO2-equivalent (a value which includes the effect of methane) above 470 ppm, just under the upper stability limit of the Antarctic ice sheet, with current rate of CO2 emissions from fossil fuel combustion, cement production, land clearing and fires of ~9.7 billion ton of carbon in 2010, global civilization faces the following alternatives:
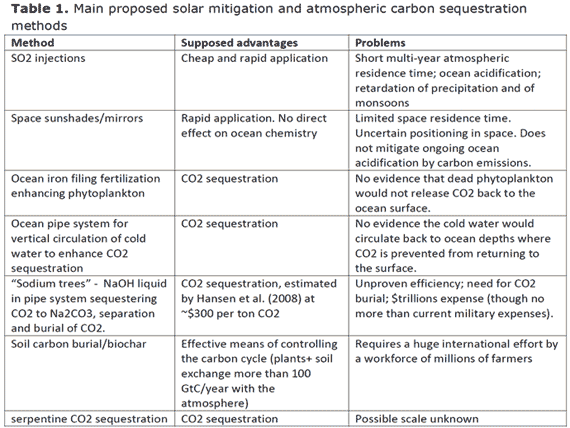
As indicated in Table 1, the use of short-term solar radiation shields such as sulphur aerosols cannot be regarded as more than a band aid, with severe deleterious consequences in terms of ocean acidification and retardation of the monsoon and of precipitation over large parts of the Earth.
By contrast, retardation of solar radiation through space sunshade technology may allow time for CO2 draw-down. Unlike sulphur dioxide injections this will not have ocean acidification effects – an effort requiring a planetary defense project by NASA.
Dissemination of ocean iron filings aimed at increasing fertilization by plankton and algal blooms, or temperature exchange through vertical ocean pipe systems, are unlikely to constitute effective means of transporting CO2 to relatively safe water depths.
By contrast to these methods, CO2 sequestration through fast track reforestation, soil carbon, biochar and possible chemical methods such as “sodium trees” and serpentine (combining Ca and Mg with CO2) may be effective, provided these are applied on a global scale
Such efforts will require an effective planetary defense effort on the scale currently expended on military spending (totaling more than $20 trillion since WWII).
It is likely that a species which decoded the basic laws of nature, split the atom, placed a man on the moon and ventured into outer space should also be able to develop the methodology for fast sequestration of atmospheric CO2. The alternative, in terms of global heating, sea level rise, extreme weather events, and the destruction of the world’s food sources is unthinkable.
Good planets are hard to come by.
Posted by Andrew Glikson on Thursday, 14 February, 2013
 |
The Skeptical Science website by Skeptical Science is licensed under a Creative Commons Attribution 3.0 Unported License. |