I've just uploaded the ratings provided by the scientists who rated their own climate papers, published in our peer-reviewed paper "Quantifying the consensus on anthropogenic global warming in the scientific literature". This is an opportunity to highlight one of the most important aspects of our paper. Critics of our paper have pointed to a blog post that asked 7 scientists to rate their own papers. We'd already done that, except rather than cherry pick a handful of scientists known to hold contrarian views, we blanket emailed over 8,500 scientists. This resulted in 1,200 scientists rating the level of endorsement of their own climate papers, with 2,142 papers receiving a self-rating.
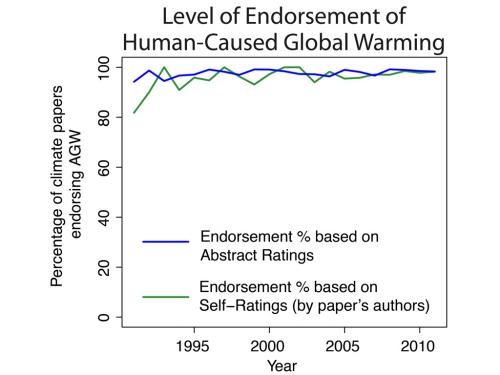
While our analysis of abstracts found 97.1% consensus among abstracts stating a position on anthropogenic global warming (AGW), the method of self-rating complete papers independently found 97.2% consensus among papers self-rated as stating a position on AGW. This independent confirmation demonstrates how robust the scientific consensus is. Whether it's Naomi Oreskes' original analysis of climate research in 2004, Doran and Kendall-Zimmerman (2009) surveying the community of Earth scientists, Anderegg et al. (2010) analysing public declarations on climate change, or our own independent methods, the overwhelming consensus consistently appears.
Figure 1: Percentage of climate papers stating a position on AGW that endorse human-caused global warming. Year is the year of publication.
That's not to say our ratings of abstracts exactly matched the self-ratings by the papers' authors. On the contrary, the two sets measure different things and not only are differences expected, they're instructive. Abstract ratings measure the level of endorsement of AGW in just the abstract text - the summary paragraph at the start of each paper. Self-ratings, on the other hand, serve as a proxy for the level of endorsement in the full paper. Consequently, differences between the two sets of ratings are expected and contain additional information.
The abstracts should be less likely to express a position on AGW compared to the full paper - why expend the precious real estate of an abstract on a settled fact? Few papers on geography bother to mention in the abstract that the Earth is round. Among papers for which an author's rating was available, most of the papers that we rated as expressing "no position on AGW" on the basis of the abstract alone went on to endorse AGW in the full paper, according to the self-ratings.
We also found that self-ratings were much more likely to have higher endorsement level rather than lower endorsement levels compared to our abstract ratings; four times more likely, in fact. 50% of self-ratings had higher endorsements than our corresponding abstract rating, while 12% had lower endorsement. Here is a histogram of the difference between our abstract rating and self-ratings. For example, if we rated the abstract as no-position (a value of 4) and the scientist rated the paper as implicit endorsement (a value of 3), then the difference was 1.
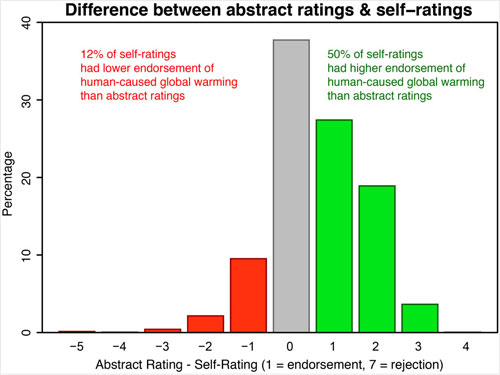
Figure 2: Histogram of Abstract Rating (expressed in percentages) minus Self-Rating. 1 = Explicit endorsement with quantification, 4 = No Expressed Position, 7 = Explicit rejection with quantification. Green bars are where self-ratings have a higher level of endorsement of AGW than the abstract rating. Red bars are where self-ratings have a lower level of endorsement of AGW than the abstract rating.
In accordance with the confidentiality conditions stipulated beforehand, we had to anonymise the self-rating data in order to protect the privacy of the scientists who filled out our survey. However, even with anonymised data, it's still possible to identify scientists due to many papers having a unique combination of year, abstract category and abstract endorsement level. Therefore, I've further anonymised the data by only including the Year, Abstract Endorsement Level and Self-Rating Endorsement Level. But even in this case, there were six self-rated papers with a unique combination of year and abstract endorsement level. So to maintain privacy, I removed those six papers from the sample of 2,142 papers.
In cases where we received more than one self-rating for a single paper (e.g., multiple authors rated the same paper), the self-rating was the average of the two ratings.
Posted by John Cook on Monday, 8 July, 2013
 |
The Skeptical Science website by Skeptical Science is licensed under a Creative Commons Attribution 3.0 Unported License. |