Over the holiday break here in San Diego, I had the rare experience of having a good bit of spare time combined with lousy weather. As a result, I had the time to try out something that I had been thinking about for awhile: If I were to code up the most brain-dead simple implementation of NASA's global-temperature anomaly algorithm, how would my results compare with NASA's? In addition, how much of an impact would all of those evil temperature data *adjustments* have on global-scale averages?
So I rolled up my sleeves and got to work. Getting a crude app up and running didn't take all that long (and I'm not the fastest coder around, not by a long-shot!). The trickiest part was dealing with the varying-length data-gaps in the GHCN (Global Historical Climatology Network) temperature data (but the C++ Standard Template Library made that task much easier).
The app I wrote reads in GHCN v2 temperature data files and computes simple "straight averages" of all the individual temperature station anomalies. I follow a procedure pretty similar to NASA's: For each station, I calculate the average temperature for each month over the period 1951-1980. I then compute individual station temperature anomalies relative to the baseline values, NASA-style. Then I just average them together. No fancy gridding or geospatial weighting – I use a simple brain-dead averaging procedure. Finally, I run the output anomaly data through a moving-average filter to smooth the results. (I applied an 11-year moving-average filter to all the results shown below.)
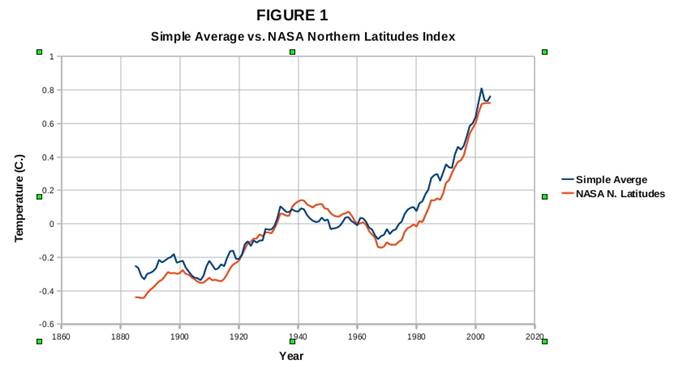
Well, this very simple procedure ended up giving me results that were pretty similar to NASA's "Northern Latitudes" temperature index, as seen in Figure 1 below. (The NASA results were smoothed with the same 11-year moving-average filter that I applied to my own results). Given that a lion's share of the GHCN stations are located in the temperate latitudes of the Northern Hemisphere, it shouldn't be too surprising that my “simple-average” procedure produced results similar to NASA's “Northern Latitudes” index.
In fact, my results showed considerably *more* warming than all of the global-scale temperature index results shown on the NASA/GISS web-site *except* for NASA's "Northern Latitudes" index. So it turns out that all the effort that the NASA folks put into "cooking their temperature books", if anything, *reduces* their warming estimates. If they wanted to exaggerate the global-warming threat, they could have saved themselves a lot of trouble by computing simple averages. Go figure!
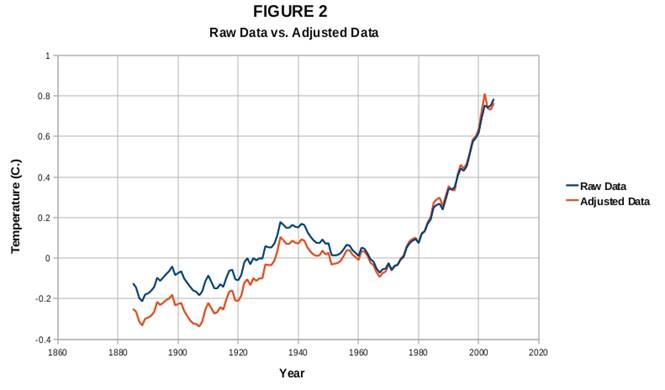
I also found that the differences between my results for raw vs. adjusted GHCN data were quite modest, as seen in figure 2 below. My raw and adjusted temperature results were nearly identical for the most recent 40 years or so. As you go back further in time, the differences become more apparent, with the adjusted data showing overall lower temperatures than the raw data earlier in the 20th century. I haven't really investigated the reasons for this bias, but I suspect that temperature-station equipment change-outs/upgrades over the past century may be a major factor. But the bottom line here is that for the most rapid period of warming (the past 40 years or so), the adjusted and raw temperature data generate remarkably consistent results.
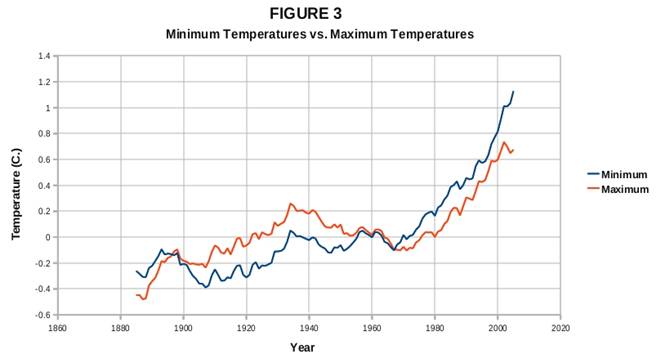
I also noted a couple of interesting things when I looked at my results for the GHCN monthly-minimum and monthly-maximum data. Figure 3 (below) shows my minimum vs. maximum temperature results (using GHCN adjusted data). My results turned out to be entirely consistent with what we know about climate forcings over the past century or so. My results show monthly-maximum temperatures rising at least as fast as the monthly-minimum temperatures during the 1910-1940 warming period. But my post-1970 results show monthly-minimum temperatures rising faster than monthly maximum temperatures. These results are entirely consistent with greater CO2 forcing later in the century than earlier. My results also show that during the mid-20th-century cooling period, maximum temperatures declined more rapidly than did minimum temperatures – these results are consistent with the aerosol-forced cooling as a plausible contributor to that cooling trend.
Now, my little project didn't produce any exciting or groundbreaking results. But it *did* show how easy it is for an average layperson with very run-of-the-mill programming skills to perform some simple validation checks of NASA/NOAA/CRU's global temperature estimates.
And one final note regarding the temperature data: NASA does not compute temperature anomalies prior to 1880 for a good reason. Data coverage and quality fall off drastically prior to the late 19th century, and just can't be used to compute meaningful global averages.
One of the important take-home lessons here is that all of the temperature data and software tools are available **for free** to anyone who wants to test the basic validity of the global surface temperature record. That includes you, WUWT partisans!
In fact, what I find remarkable is that in spite of the incredible concern that the surfacestations folks have expressed about the quality of the surface temperature data, how little effort they have put forth to analyze any of the data that they have so vocally criticized! The surfacestations project has been existence for, what, close to four years now? And as far as I can tell, I crunched a lot more temperature data over my holiday break than the surfacestations project has in its entire existence!
To the global-warming "skeptics", I have this to say: Never in history has science been more accessible to the general public than it is now. And of all the scientific disciplines, climate-science is perhaps the most open and accessible of all. There is a treasure-trove of *free* software development and data analysis tools out there on the web, along with more *free* climate-science data than you could analyze in a hundred lifetimes!
So instead of sniping from the sidelines, why don't you guys roll up your sleeves, get to work and start crunching some data? Don't know how to program? With all the free software, tutorials and sample code out there, you can teach yourselves! Computing simple large-scale temperature averages from the freely-available surface temperature data is closer to book-keeping than rocket-science. It just isn't that hard.
I spent some time cleaning up and commenting my code in the hope that others might find it useful, and I'm making it available along with this post. ( A valgrind run turned up a couple of real bonehead errors, which I fixed – note to myself: code *first*, and *then* drink beer).
The code isn't really very useful for serious analysis work, but I think that it might make a good teaching/demonstration tool. With it, you can do simple number-crunching runs right in front of skeptical friends/family and show them how the results stack up with NASA's. (NASA's “Northern Latitudes” temperature index is the best one to use as a comparison). It might help you to convince skeptical friends/family that there's no “black magic” involved in global temperature calculations – this really is all very straightforward math.
Instructions for compiling/running the code are in the GHCNcsv.hpp file, and are summarized here (Assuming Linux/Unix/Cygwin environments here).
UPDATE: 2011/01/25
Due to my failure to RTF GHCN documentation carefully, I implemented an incorrect algorithm. It turns out that multiple stations can share a single WMO identification number. Having failed to read the documentation carefully, I charged ahead and coded up my routine assuming that each temperature station had a unique WMO number.
So what happened was that in the cases where multiple stations share a WMO id number, my program used temperature data from just the last station associated with that WMO number with valid data for a given year/month.
However, that goof actually *improved* the results over what you would get with a true "dumb average", as Kevin C discovered when he went to reimplement my routine in Python.
It turns out that many temperature stations have random data gaps. So what happened is in cases where multiple stations share a single WMO id, my routine quite accidentally "filled in" missing data from one station with valid data from other stations. That had the effect of crudely merging data from very-closely-spaced clusters of stations, reducing the overweighting problem associated with dumb-averaging, and reducing the impact of big data gaps in single-station data on baseline and anomaly computations.
Kevin C demonstrated that a true "dumb average" gives significantly worse results that what I computed.
So I went back and tried a little experiment. I changed my code so that the temperature data for all stations sharing a single WMO id were properly averaged together to produce a single temperature time-series for each WMO id.
When I did that, my results improved significantly! The differences in the results for raw vs. "adjusted" GHCN were reduced noticeably, showing an even better match between raw and adjusted temperature data.
So quite by accident, I stumbled on a method considerably simpler than proper gridding that still gives pretty decent results!
This turned out to be a quite accidental demonstration of the robustness of the surface temperature record! I misinterpreted the GHCN data format and still got results darned close to NASA's "Northern Latitudes" index.
I'd like to say, "I meant to do that", but instead I should say thanks to Kevin C for uncovering my dumb mistake.
UPDATE 2 (2011/01/28)
Here's the code for the fixed ReadTemps() method. Replace the existing ReadTemps() code in GHCNcsv.cpp with this version (indentation is messed up -- but a smart editor can fix that automatically):
Oh, $#@! The html parser keeps munching the template declarations. Here's a link to the corrected code instead:
UPDATE 3: (2011/02/11)
There's an embarrassing "off-by-one" hiccup in the ComputeMovingAvg and ComputeMovingAvgEnsemble routines. Eliminating the first "iyy_trailing++" statement in each routine should fix the problems.
The latest code (with a simple gridded-averaging implementation in addition to fixes for the above bugs) can be downloaded from here: http://forums.signonsandiego.com/attachment.php?attachmentid=8142&d=1297529025
UPDATE 4 (2011/02/16)
New software version here: http://www.filefactory.com/file/b571355/n/ghcncsv4.zip
Now allows users to test the denier "dropped stations" claim (-Y command-line option)
-Y -1:1995:2005 means process data excluding no stations, then process data excluding stations that stop reporting data before 1995, then process data excluding stations that stop reporting data before 2005 -- each result is put into a separate csv column.
Posted by caerbannog on Sunday, 16 January, 2011
 |
The Skeptical Science website by Skeptical Science is licensed under a Creative Commons Attribution 3.0 Unported License. |