This is a re-post from the Climate Brink by Andrew Dessler
In the world of climate communications, no claim seems to come up more frequently than “The climate models are wrong!” We recently wrote a post responding to claims that the models are running cold and future warming will be larger than models predict.
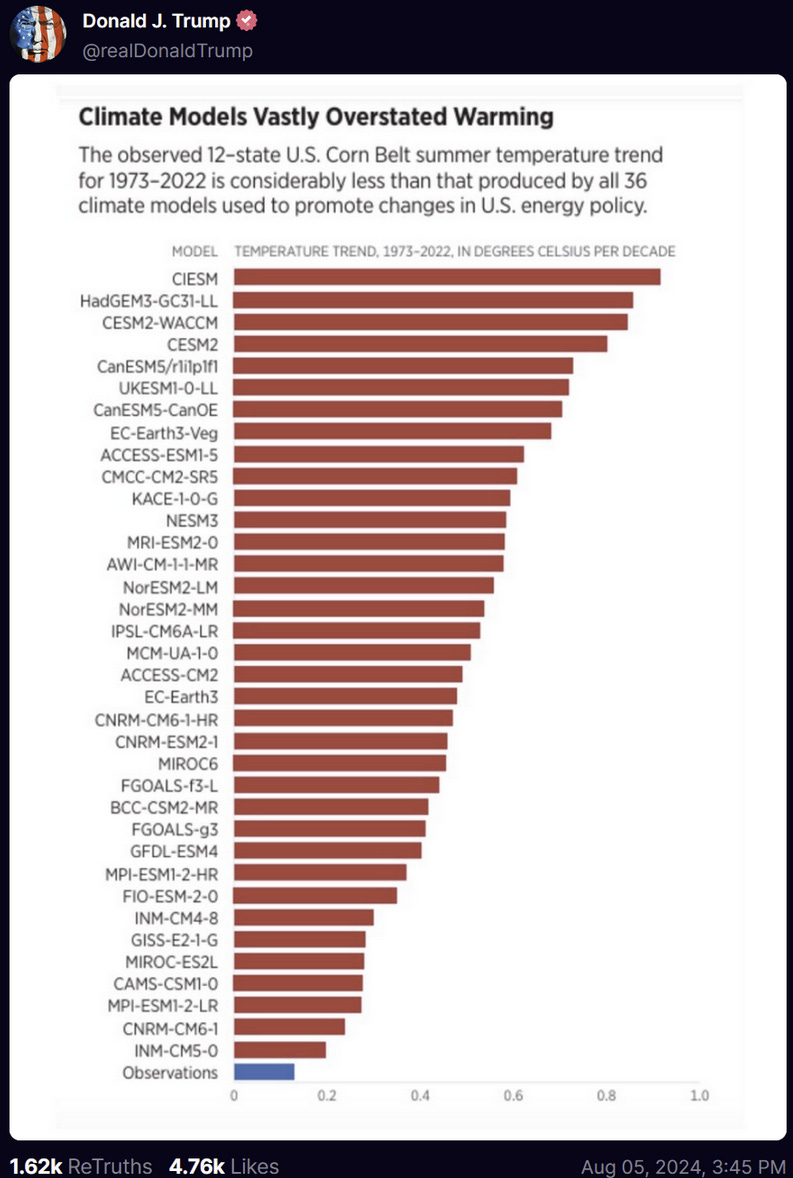
Today, it’s the claim that the models are hot and future warming will be much less than they predict. The source is some internet weirdo named Derwood Turnip, who posted this:
First, let’s be clear: climate models have an admirable track record of predicting the global average temperature. Zeke wrote a paper about that and it’s worth bookmarking so you’re ready to respond to anyone who says models are bad.
But Derwood’s post is about regional and seasonal climate change. While there are few details provided in the source document, I was able to reproduce the general result presented. So does this mean that models are warming too much?
While the global average temperature is well constrained by planetary energy balance, how that warming is distributed around the planet can vary greatly due to what we refer to as unforced variability. This phenomenon is similar to the randomness we observe in weather patterns, but are driven by the ocean circulation on much longer time scales, such as the El Niño/La Niña oscillations.
Unforced variability can warm one region while simultaneously cooling another, with such variations spanning decades. This long-term variability adds a layer of complexity to prediction of regional climate change, even as the global average warming trend is well constrained.
As an example, you can take a climate model and run it many times, with identical emissions of carbon dioxide, but with each run starting with a slightly different state of the climate system. For these runs, the global average temperature change is similar, but how the warming is distributed varies greatly:

In some of the ensemble members (e.g., C16, C28), the Southeast U.S. cools between 2010 and 2060, while in most others it warms. In some members (e.g., C4, C29, C40), the Pacific Northwest cools, while in most others it warms.
This has important implications for Derwood’s plot. To see this, let’s take a single model, in this case, ACCESS-ESM1-5, which has an ensemble of 40 historical runs in the CMIP6 archive. Each run has different initial conditions, so each run of the model will have a different pattern of warming and cooling, just like we see in the plot above.
Summertime central U.S. warming in this one model ensemble looks like this:
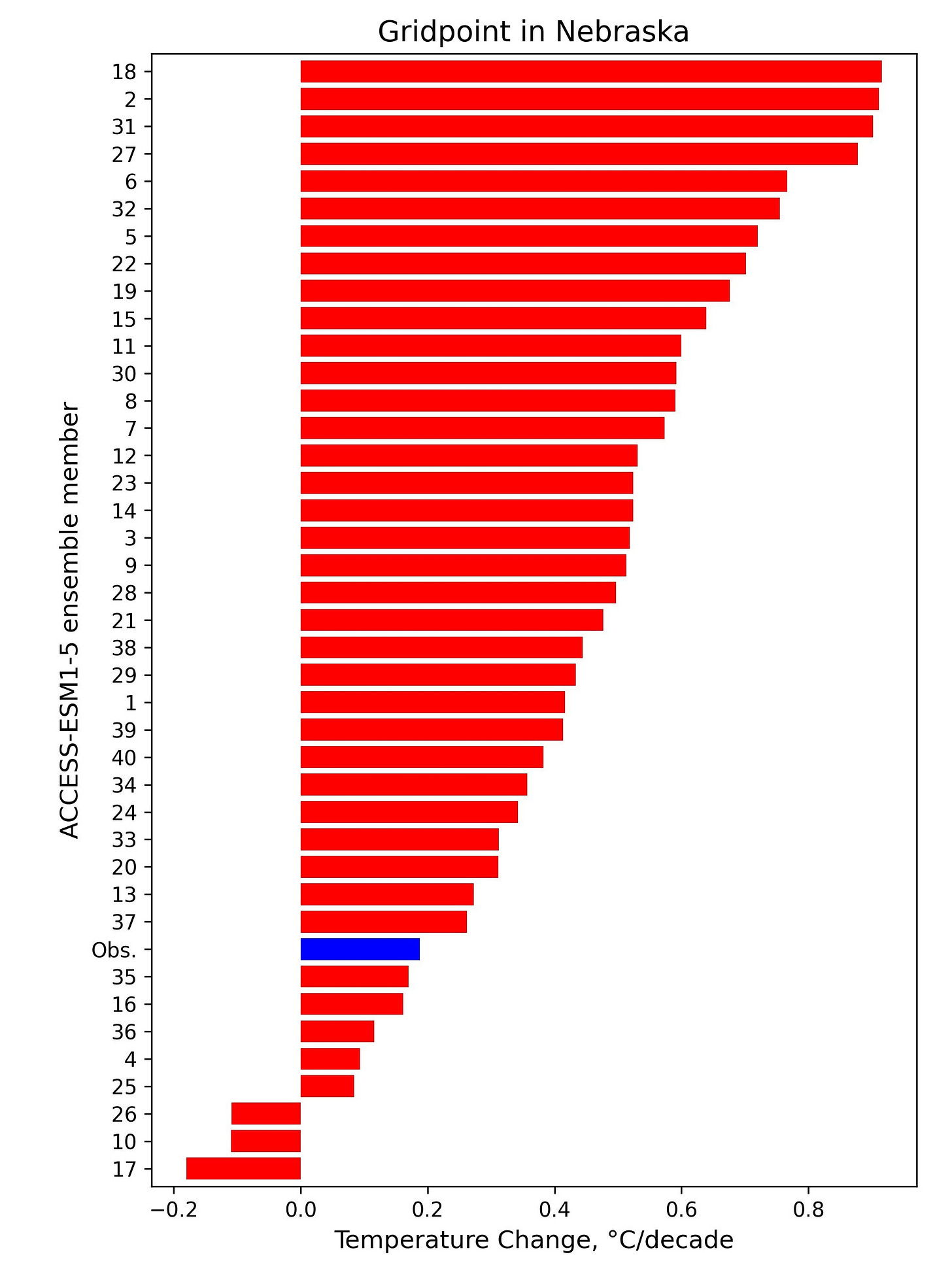
Wow! Unforced variability has a huge impact on what this model predicts. 20% of the runs show smaller warming than observations, and 8% show cooling. At the other end, there are ensemble members that show five times the observed warming. This spread is due entirely to different initial conditions, so this is an example of chaos in a strongly non-linear system.
So is the model overestimating warming or not? There’s no way to know. If you pick ensemble member 17, the model is underestimating the warming. If you pick ensemble member 35, the model is doing a fantastic job, while ensemble member 18 is overestimating the warming.
Without figuring out which of these ensemble members has unforced variability matching the unforced variability in the real world (this is really hard, by the way), the only correct conclusion is that the observed warming falls within the envelope of warming predicted by this model, so you cannot conclude that the ACCESS-ESM1-5 is overestimating warming.
This doesn’t mean that this model is right, of course. But it does mean that Derwood’s plot, which shows one value for this model, ~0.6°C, is bullshit. Probably not a surprise to anyone smart enough to read The Climate Brink.
To construct Derwood’s plot, I’m guessing a random run of each model was selected. So let’s remake Derwood’s plot, but using the ensemble member from each model that shows the lowest warming in this region. I limit myself to models that have ensembles with at least five runs in the CMIP6 archive.
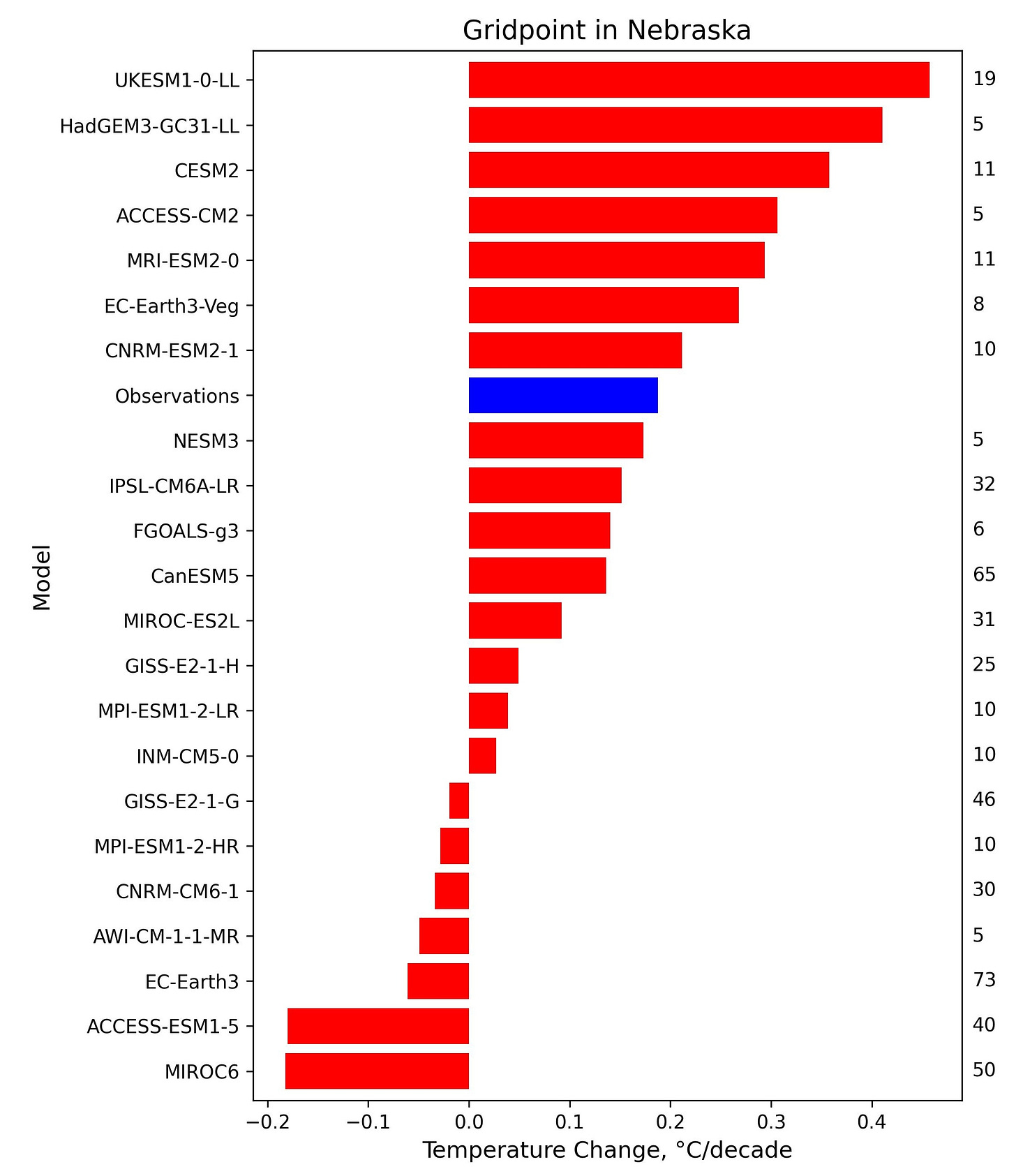
This shows that the results of the ACCESS-ESM1-5 are generalizable. Two thirds of the CMIP6 models produce warming lower than observations in their ensembles. Again, this doesn’t prove the models are right, but it does say that naive comparisons that ignore unforced variability, like Derwood’s plot, should not be taken seriously.
While unforced variability can impact any single location, if you look globally, the impact of it cancels out — regions that are cooled by unforced variability are cancelled by other regions that are warmed. Thus, the right way to do this calculation is globally.
To that end, I’ve taken a single (random) run of each of the 45 CMIP6 models and the observations and calculated this same change in summertime surface temperature, but at each point on the globe.
If the CMIP6 models are accurately simulating the climate, I would expect that areas where the model average is warming faster than the observations would be about equal to the area where the model average is warming slower.
In reality, the average warming in the CMIP6 models exceeds observed warming over 63% of the area of the Earth. This is larger than our expected 50%, but it is consistent with analyses showing that a subset of CMIP6 models does appear to be running too hot.
If we eliminate these too-hot models by screening out the models that have equilibrium climate sensitivity that’s out of the accepted range (2C-4C)1, then the average warming of the models exceeds observations over 48% of the area of the Earth, with observed warming exceeding the models over the other 52%.
This is exactly what we would expect if the models are accurately simulating the climate system.
This plot below shows the difference between the average of the screened model ensemble and the observations. Red colors indicate where the average model warming is faster than observations while blue areas show that models are warming slower. As mentioned above, 52% of the globe is blue, indicating places where the models are warming slower than observations.
The box over North America shows the region that Derwood’s plot focuses on.
[very John Mulaney voice] It’s weird … isn’t it weird … it’s weeeirrrd … that the region they picked just happens to be the place in the Northern Hemisphere where models look the absolute worst?
I have two comments on the selection of this region. First, I think it’s useful to understand the provenance of this plot. It comes from Dr. Roy Spencer via the Heritage Foundation. I won’t discuss in detail my tortured history with Roy other than to say that, when I see a scientific result from him, my baseline assumption is that he’s dishonestly manipulated the analysis to downplay the seriousness of climate change2.
In this case, it looks to me like Spencer intentionally selected this particular region to make models look bad. If so, it wouldn’t be the first time he’s done something like that. In a 2011 paper, I criticized Spencer for doing something similar:
There are three notable points to be made. First, [Spencer and Braswell] analyzed 14 models, but they plotted only six models and the particular observational data set that provided maximum support for their hypothesis. Plotting all of the models and all of the data provide a much different conclusion.
I can't read Spencer's mind to say for certain that he did this knowingly. However, the fact that he pinpointed the exact location where models perform the worst seems like too much of a coincidence to be anything other than intentional. But I’ll leave it to each of you to make that judgment for yourself.
The other comment is that, in addition to unforced variability, this is a region where other odd things are going on. Here are two papers that talk about why this region is warming less than expected during summertime. It turns out that this is the most agriculturally productive region on the planet, and land-use changes over the last few decades have largely offset greenhouse gas warming here.
To the extent that models have problems in this very small region, it’s much more likely to be connected to how well the models are handling land-use changes, not how well they represent global warming.
Over my career, I've devoted considerable effort to comparing climate models with observations and have concluded that climate models perform surprisingly well, even on things I wouldn’t expect them to.
The saying “all models are wrong, but some are useful” applies here — climate models are far from perfect, but they are also incredibly informative. Most of the criticisms of models are based on bogus, misleading analyses. This one is no exception.
Update: a loyal reader pointed out that Gavin Schmidt made many of these same points on RealClimate in January. It’s an excellent write-up so go read it.
Posted by Guest Author on Monday, 19 August, 2024
 |
The Skeptical Science website by Skeptical Science is licensed under a Creative Commons Attribution 3.0 Unported License. |
{kind=link}