






























 Arguments
Arguments





















The EPA debunked Administrator Pruitt’s latest climate misinformation
Posted on 12 February 2018 by dana1981
Last week, a Las Vegas news station interviewed Trump’s EPA administrator Scott Pruitt. The interviewer brought up the topic of climate change, and virtually everything Pruitt said in response was wrong, and was often refuted on his own agency’s website, until he started deleting it.
Humans are causing global warming. All of it.
To begin, Pruitt claimed that we don’t know ‘with precision’ what’s causing global warming.
Our activity contributes to the climate changing to a certain degree. Now measuring that with precision, Gerard, I think is more challenging than is let on at times.
Here’s what the EPA website said about that a year ago, before Pruitt got a hold of it as part of the Trump Administration’s systematic deletion of government climate change websites:
Research indicates that natural causes do not explain most observed warming, especially warming since the mid-20th century. Rather, it is extremely likely that human activities have been the dominant cause of that warming.
To support this statement, the EPA referenced the latest IPCC report. The IPCC concluded with 95% confidence that humans are the main cause of global warming since 1950, with a best estimate that humans are responsible for all of the global warming during that time. That’s what the scientific research has overwhelmingly concluded:
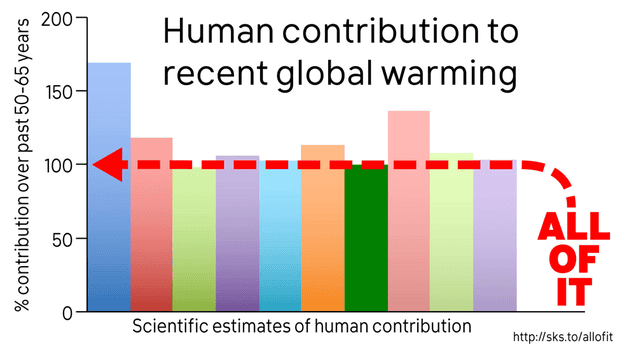
The percentage of human contribution to global warming over the past 50-65 years from various peer-reviewed studies. Illustration: Dana Nuccitelli and John Cook
Similarly, the EPA’s Student’s Guide to Climate Change (which has survived the Trump purge) says:
The Earth is getting warmer because people are adding heat-trapping gases to the atmosphere, mainly by burning fossil fuels … People are causing these changes, which are bigger and happening faster than any climate changes that modern society has ever seen before.
It’s bad
Pruitt later shifted gears to repeat the third most popular climate myth:
I think there’s assumptions made that because the climate is warming, that that necessarily is a bad thing.
This is not a matter of assumptions – it’s a conclusion supported by a vast body of scientific research. The EPA website likewise tackled this one, until Pruitt got his hands on it:
Scientific studies indicate that extreme weather events such as heat waves and large storms are likely to become more frequent or more intense with human-induced climate change.
And the EPA’s Student’s Guide to Climate Change addresses it:
The negative impacts of global climate change will be less severe overall if people reduce the amount of greenhouse gases we’re putting into the atmosphere and worse if we continue producing these gases at current or faster rates.
The EPA’s Climate Change Indicators page likewise lists a number of dangerous climate change consequences. Quite simply, more intense droughts, floods, and hurricanes, and coastal inundation from sea level rise are all very bad outcomes. And even the rosiest analyses conclude that any further global warming will be bad for the economy.
The ideal climate is a stable one
In fact, not only did Pruitt suggest the consequences of global warming won’t be bad, he seemed to think they’ll be good and humans will “flourish.”
Is it an existential threat - is it something that is unsustainable, or what kind of effect or harm is this going to have? We know that humans have most flourished during times of, what, warming trends? … Do we know what the ideal surface temperature should be in the year 2100 or year 2018? It’s fairly arrogant for us to think we know exactly what it should be in 2100.
I asked climate scientists to answer this ‘ideal temperature’ question last month. They all agreed that the ideal climate is a stable one. Pruitt is wrong to say humans flourished during warming trends – we flourished during times of relatively flat temperatures without rapid trends. Climate scientist Katharine Hayhoe explained:
There is no one perfect temperature for the earth, but there is for us humans, and that’s the temperature we’ve had over the last few thousands of years when we built our civilization, agriculture, economy, and infrastructure. Global average temperature over the last few millennia has fluctuated by a few tenths of degrees; today, it’s risen by nearly 1°C and counting.
Why do we care? Because we are perfectly adapted to our current conditions…
Pruitt’s goal with these answers is clearly to manufacture doubt – to make people think that we needn’t take urgent action to slow global warming because the outcome might not be so bad. But that argument ignores the vast body of scientific evidence that clearly shows the net consequences of continued rapid climate change will fall somewhere in the range of bad to catastrophic. I summarized some of those consequences in this Denial101x lecture:
Pruitt’s fossil fuel agenda slips out
Toward the end of the interview, Pruitt let slip his allegiance to the fossil fuel industry:
Renewables need to be part of our energy mix, but to think that’s going to be the dominant fuel, or dominant energy source on how we generate electricity, I think is simply fanciful … There was a declared war on coal. The EPA was weaponized against certain sectors of our economy – fossil fuels generally - and that’s not the role of a regulator.
First of all, under the Obama administration, the EPA regulated carbon pollution because it was legally required to do so under the Clean Air Act, according to the Supreme Court. That’s not being ‘weaponized’ against fossil fuels, it’s called enforcing the law to protect Americans’ health.
Second, there is no reason why renewables couldn’t be the dominant fuel in our energy mix. In fact, several states have renewable portfolio standards and goals to make that happen. For example, Hawaii aims for 100% renewable energy by 2045, and California and New York have targets of 50% renewables by 2030. California is even ahead of schedule, on track to meet that goal a decade early, by 2020.
Lies about the Paris agreement
As if his misinformation about climate science and clean energy weren’t bad enough, Pruitt really laid it on thick when asked about the Paris climate accords.
[Paris] was a bad business deal for this country … it was not about CO2 reduction. If it was about CO2 reduction, they would not have let China and India take until 2030 to reduce their CO2 footprint.
In reality, the Paris agreement couldn’t have been a better deal.









It's hard to see how to ignore the political nature of Administrator Pruitt's activities, but I'll confine myself to saying he's unscientific. James Hansen's analysis is conclusive, and see Alex Cannara on "the Evil Twin or Global Warming"
There are three schools of thought.
0 / There is no such thing as human caused global warming.
1/ It can be cured by using the products of recent sunshine.
2/ It can only be cured by using the products of ancient supernova catastrophes.
There are people who think that the third option above, nuclear, can be "part" of the solution, along with what is popularly called "renewables", but a careful analysis shows that renewables of the solar origin sort, other than hydro when it has received sufficient H2O precipitation, is not at all dispatchable. Therefore it needs backup. If that backup is non-fossil, then it is Gen IV nuclear. If you have enough geothermal, hydro, and nuclear to meet peak demand, you gain nothing from intermittent renewables.
CS:
Can you provide a peer reiviewed citation to support your wild claim that nuclear can provide even10% of total power?
Abbott 2011 gives 14 reasons why nuclear is completely impractical. Please address at least 4 of them in your citations. They include: 15,000 sites to locate reactors do not exist, not enough rare elements like hafnium and beryllium exist, the expected accident rate would be one major accident per month, and there is not enough uranium in known reserves.
I note that to power the world countries like Iran, Syria, North Korea and Zimbabwe would have to install nuclear.
Conradin Sakison I agree with your comment about Pruits political motivations.
"If you have enough geothermal, hydro, and nuclear to meet peak demand, you gain nothing from intermittent renewables."
The operative word is of course "if". Geothermal power is a limited resource, with only 10 countries using it significantly as below.
sustainabletechnologyforum.com/which-countries-produce-the-most-geothermal-electricity_21870.html
While capacity does exist in some other countries particularly in Africa, building geothermal plant is significantly more expensive than wind and solar power. I live in NZ which is a relatively young country geologically, and very seisimically active being on a plate boundary, and we have geothermal power, but its only sufficient for part of our electricity needs, and we are building wind power as well. I have no opposition to geothermal its great power, but we need to be accurate about the availability and costs.
Hydro electricty is nearly "maxed out" in many countries with the larger rivers already utilised. Building more dams is contentious, because of the environmental impacts on wildlife and local communities.
Nuclear power comes up against a long list of problems as pointed out above.
Therefore as a general rule globally, it appears that the primary focus is going to be on wind and solar , with hydro and geothermal providing supplementary power, or peaking electricity supply in the background, along with storage strategies and some limited use of gas.
Honestly Pruitt would drive anyone to total despair.
"The EPA was weaponized against certain sectors of our economy – fossil fuels generally - and that’s not the role of a regulator."
Pruits use of the term "weaponises" uses inflammatory, manipulative language to appeal to emotion, combined with a strawman fallacy. Quite a combination of rhetorical click bait, and unbecoming of someone 'leading' an organisation. And at least my clickbait is accurate.
And it is actually the job of the regulator to regulate fossil fuels. From Investopedia "The Environmental Protection Agency (EPA) was established in December 1970 under United States President Richard Nixon. The EPA is an agency of the United States federal government whose mission is to protect human and environmental health. "
"Warming is good for humanity"
No it isn't. The article summed it up well. Humanity elected the IPCC to do the in depth research on whether climate change is a problem, so that we aren't reliant on the views of one person, with all the baggage individuals have. Its foolish to now loose faith in The IPCC, or to subscribe to the views of people like Pruitt, who have a huge anti enviromental history, and thus a clear bias.
Conrad,
I'm quite curious to see the analysis of which you speak which indicates that solar power is not dispatchable. Certainly, you can't "turn on" more solar panels to meet peak demand when there are clouds, it is night time, etc, but a robust power storage system will still allow a solar powered grid to meet demand when demand peaks. There have been notable recent advancements in solar power that now allow many solar power plants to supply the grid in much the same way as older fossil fuel or hydropower plants were able to load follow. Specifically, concentrated solar power plants use concentrated solar radiation to melt salts or other substances, which are then used to generate electricity thermally, and the molten salts are stored to meet later peaks in electricity demand.
If Pruitt opposes renewable energy like wind power, he is just hurting the American People, given its now cheaper than coal, as well as lower CO2 emissions, and it also causes less respiratory health problems. I don't think there can possibly be any logical argument otherwise. I dont live in America, so it's just my observation.
Speaking of heads of organisations we have the following:
"Trump’s Science Advisor, Age 31, Has a Political Science Degree
Because Trump has not nominated someone to head the Office of Science and Technology Policy, Michael Kratsios is the de facto leader."
www.scientificamerican.com/article/trump-rsquo-s-science-advisor-age-31-has-a-political-science-degree/
Can anyonee believe the cynical, destructive, ideologically driven anti science agenda here? Political science is not a hard physical science, or even much of a science at all.
"Kratsios graduated from Princeton in 2008 with a political science degree and a focus on Hellenic studies. He previously served as chief of staff to Peter Thiel, the controversial Silicon Valley billionaire and Trump ally."
"The vacancy might reflect Trump's skepticism on climate change. If the president believes that the Senate would balk at a nominee who questions widely accepted views on climate change, he might prefer to leave the post open, said William Happer, an emeritus physics professor at Princeton University who is considered a leading candidate for the job. Happer says the Earth is experiencing a "CO2 famine."
"There is no problem from CO2," Happer said last month in an interview with E&E News (Climatewire, Jan. 25)."
You couldn't make this stuff up. If it was an idea for a fiction book or movie, it would be rejected as too implausible. But no, it's actually happening.
nigelj: We also have this...
Trump seeks big cuts to science across agencies by Scott Waldman, E&E News, Feb 13, 2018
Luckily, the US Presidents' budget proposals are rarely, if ever, enacted as proposed. This one will be no different.
Sweet at 03:16, 13 feb
Please look at the graph in Wiki https://en.wikipedia.org/wiki/Abundance_of_the_chemical_elements#/media/File:Elemental_abundances.svg
There is far more Halnium on earth than there is uranium.
Halfnium is used as a neutron absorber in a nuclear reactor and absorbers are only necessary in small amounts in civilian reactors. Its use is mainly needed for naval reactors where high power to weight ratio is essential and the fuel is highly enriched and so a greater proportion of neutron absorber is required. Civilian reactors use low enriched fuel less than 5% U235 and use far less absorber than a naval reactor. Neutron absorbers are only a minor component in a civilian reactor (but very important) In fact netron absorbers lower the reactivity of the reactor and so the leas used the better. For civilian reactors there is absolutley no need to use halfnium it is a design choice since there are many other absorbers that are also used such as boron (100 times more abundant than uranium) and considerably cheaper than hafnium, gadolinium and samarium. At a push cadmium may be used but is toxic.
I could go through the rest of your diatribe but will give you a couple examples, 70 % of the electricity generated by France is from nuclear power (40 % of total energy) If France can do it the the rest of the world can.
https://en.wikipedia.org/wiki/Nuclear_power_in_France
. It has found space to put them, and exports electricity to Britain and Germany.
"I note that to power the world countries like Iran, Syria, North Korea and Zimbabwe would have to install nuclear".
You should read the news a bit more Iran and North Korea already have nuclear power
Now for the finite uranium resource. In the current type of reactors U-235 is almost exclusively the only fuel. It is present at 0.711% in natural uranium and using current enrichment techniques just over a half of the material is extraced into the fuel, the rest remains in the tails for future extraction.
The rest of the uranium, mainly U-238 can be used in an other design of reactor. which leads us to 99 times the current fuel resouce. In addition thorium can also be used to fuel reators in which there is a further ten fold abundance on earth.
It is not the lack of resource that limits the use of nuclear power but the public acceptance and the improved technology that that would require.
Alchemyst @10,
People seem to get very passionate about advocating nuclear power for some reason. Its almost a little extreme.
Please note there may be large quantities of hafnium in sea water and in zircon (?) etc but this gets expensive to extract, that is probably the significant point. Its the same issue with minerals in general, and they are all essentially limited finite resources ultimately.
And regardless of resource issues, not many countries are building nuclear reactors, due to capital costs, time delays and so on. You can't force it upon them.
"You should read the news a bit more Iran and North Korea already have nuclear power"
Iran only has one nuclear reactor fully operational last year I think, and gets most of its electricity by far from gas and other sources.
www.world-nuclear.org/information-library/country-profiles/countries-g-n/iran.aspx
But the real point is thousands of reactors around the world will create a real global safety risk, especially in badly run countries. These sorts of accidents don't respect borders. You could do a complicated costs benefit analysis, but I still don't like it too much.
I confess I grew up during the three mile island scare and chernobyl, and these things imprinted a little on me and made me sceptical, but clearly these disasters were still pretty serious. I think I have it in perspective, and the safety issue is still a very real concern. Chernobyl needed a concrete encasement costing billlions, and this already leaks, and needs to be replaced every 100 years basically forever.
France is a well run country, but others aren't and will have slack safety standards. You would need to be very careful in earthquake vulnerable countries, because one blunder with the design of the building and its all over. Have you seen what building standards are like in third world countries? Its shockingly poor and corrupted.
I think the nuclear advocates need a safer technology, and then you will find people will listen.
Alchemyst at 10,
I note that you have cited Wikipedia twice but have no peer reviewed data to answer my peer reviewed study that concluded that nuclear is completely impractical. I will also point out that no-one has published a response to Abbott 2011. Nuclear proponents appear to have conceded that Abbott is correct. You only responded to 2 of Abbotts 14 issues regarding nuclear. Presumably you think the others are correct. (Note: Wikipedia references to percent abundance of materials in the crust are not the same as economically recoverable reserves).
France has announced that they are expanding renewable energy and reducing nuclear.
When I go to Brave New Climate, which nuclear supporters used to cite as the go to web site for nuclear information, I see that nothing in support of nuclear has been posted in over 18 months. Barry Brooks (owner of Brave New Climate) was one of the reviewers of Abbott 2011 so he must have been convinced.
I have lost count of the number of times I have asked nuclear supporters to write an article in support of nuclear for Skeptical Science. No one who supports nuclear feels that it is worth their time to write such an article. You are welcome to write the article. If you cite peer reviewed data (Wikipedia is not good enough) it will probably get posted.
I have thought about writing an article based on Abbott 2011 so that we have one location for all the pro-nuclear blather. Do other readers think it would be worth having such an article?
Here is a peer reviewed article that shows there are enough materials to manufacture all the needed wind and solar power generators. There was not enough neodynium for the wind turbines so new wind turbines have been designed that do not use neodynium.
France is certainly one of the best examples to see what widespread application of nuclar energy looks like. It was a success and then hit some limits. One of them is time: the plants are all ageing, they need extensive work to go on for another 50 years, which is quite a short time span in the grand scheme of things, especially considering that the reactors will be something to manage in some form or another for pretty much ever. Ironically, nuclear energy production is also suffering from climate change: as the waters used by the plants (outisde the closed circuit of the core) tend to be warmer and the temperatures increase, they are faced with restrictions as to how much water can be released and how warm these waters can be. Constructions of new plants has not been very well received: the one built in Finland is 10 years behind schedule and billions over budget, reflecting poorly on the industry's capability to deliver, even from actors with one of the highest expertise in the matter. The costs are extremely high. Although the problem of waste remains, it is notable that France never had a major incident, unlike the US and Russia. Japan also has an excellent record, except for the Fukushima event, which was owed mostly to poor siting. It is highly dubious, however, that such safety performance could be maintained across a wide range of less well functioning states if nuclear was to be generalized through the world as a main energy source. It shouldn't be ouright ruled out inall circumstances but it is certainly no miracle solution.
M Sweet @12
I think an article on nuclear power would make sense. It would provide some background information on strengths and weaknesses, and as you say its a place to direct nuclear commentary. In this sense, it ensures peoples opinions on nuclear aren't simply being ignored which is important in terms of balance and website image.
Theres an old saying "if it looks too good to be true, it probably is". I think nuclear power had near miraculous promise, but I remember thinking at the time it looked too good to be true. We have discovered a whole range of downsides, and other alternative electricity sources.
Best not to be closed minded of course, but I think its entirely up to the nuclear industry to provide a safe afforable version of nuclear power. I hear this talk of thorium, but if its as good as the advocates claim, why isn't it a reality?
I agree with PC @13. A world with thousands of reactors becomes problematic for numerous reasons, but we shouldn't completely rule out nuclear energy. For example if a country doesn't have other good options, but they appear to be in a minority.
I wonder if France developed nuclear power, because of limited hydro and coal reserves, and a desire not to be reliant on importing coal from germany? This is just a pure guess, and could well be wrong, but does anyone know, I couldn't find anything.
I am neutral on nuclear power - looks a good option for some parts of the world, but Abbot's review is pretty sobering. The lack of response from the nuclear industry is also rather worrying. Perhaps new technology will change things.
However, the biggest issue with nuclear world wide would seem to be lack of investors -some strong doubt as to whether investing in nuclear will make a reasonable return (if at all). If Alchemyst is so sure about the technology, then by all means buy some shares in companies wanting to build one. For me though, my money is in hydro, solar and geothermal which have all done well for me.
I think there should be a nuclear article to collect comments. As it is we have the same comments over again every two or three months. The problem is that if I write the article it will be negative. In general I do not like to read negative articles so It would be better for someone who likes nuclear to write the article. So far the people who support nuclear have not been willing to put in the effort.
The Abbot paper looks for problems but does not indicate that are solutions already known but possibly in need of development. He is basing his arguments on current designs of light water U-235 reactors where there are alternatives that have been used in the past and future designs. He also only discusses liquid metal cooled breeder reactors where alternativea are currently in development.
With regards to my diagram of elemental abundances I believe that it is the same one that Abbott used both cite USGS http://pubs.usgs.gov/fs/2002/fs087-02/
Abbott starts with a premise that future nuclear reactors will be the same design and require the same construction materials as currently used, however there are alternatives.
Halfnium is used as a control rod /scram material, yet boron is an abundant and cheap alternative and has certainly been used in the past> Other alternatives are also used, silver and cadmium, gadolinium(bit rare)
Zirconium used for cladding the fuel rods, stainless steel , not as good but is also used.
He bases his arguments on U-235 (points 8,9 10)
fuel cycle which amounts to 0.711% of uranium. Yet thorium is 400 times as abundant as U-235.
Thorium is not fissile and is converted to U-233 in the reactor. This is done by using an initial charge of U-235 (or the dreaded Pu-239) after which as the U-235 is burned up it is replaced at a ratio of slightly grater than 1 to 1 by U-233.
Demonstration breeder reactors have been operated using U-238 fuel as well as thorium.. Many have used liquid metal as the coolant (eg sodium which is explosive in contact with water) yet in Julich, Germany a gas cooled reactor was operated for 20 years, but it did have a number of problems with contamination leaks. However pebble bed reactors do not need control rods (no halfnium) since as the temperature rises the reactivity of the reactor decreases and so do not go to meltdown. The fuel is clad in carbon and silicon carbide so no Zirconium is required. There has been an other prototype in Germany but that is shut down, There is a third currently operational in China, with another in construction.
India is currently constructing a thorium heavy water cooled reactor.
Thorium technology is largly undeveloped so we cannot write it off nor can we state that it will be the saviour. It still has the uranium cycle problems of public acceptance, potential bad practices. However as thought, to my knowledge there has only been one accidentaldeath in a civilian US Nuclear facility in the last 50 years (citation required but it was an NRC announcement some 5 years ago when it happened) and it was a non nuclear accident.
It is hard to believe but take a look at this referencehttps://www.forbes.com/sites/jamesconca/2012/06/10/energys-deathprint-a-price-always-paid/#135d6fe7709b
This is far too big a topic for me to complete and I realise that I have rambled a bit and no I will not provide peer reviewed citations because I do not have the time.
Alchemyst @18, interesting information on mortality rates for various sources of electricity. However the most relevent comparison is really nuclear against wind and solar power, and there the gap isn't so huge. I assume solar power deaths are installers falling off roofs! And yes the mortality rate per trillion watts is the important thing.
But again, remember most nuclear power is currently in well run countries like America and France. Also, its not just about mortality rates. Chernobyl polluted large areas of land, and decimated the Ukraines agricultural exports for years.
I think it's also a psychological perception issue. Nuclear accidents are scary events, even although very uncommon. Its similar to islamic terrorism in western countries. The public struggle to realise deaths from these things are low, measured against population, or watts of electricity. Not that this makes either acceptable things of course.
It won't be enough to say "safety has been improved". I suggest it will need something distinctly new to win over the public. However right now wind and solar power is proving popular with generating companies, and results like this speak larger than theoretcial claims.
Sorry for blathering on as well. But its an interesting issue.
Alchymst,
Proposed theoretical reactors that have never been built are not solutions. Abbott discusses the breeder reactors you propose. The fact that none have been able to run for significant amounts without problems tells us how likely it is that they will be useful in a reasonable amount of time. Work out a timeline: if they have a design next week it will take them 5-10 years to build. Then it will take 5-10 years to determine if the alloys they have chosen can withstand the extreme conditions in the breeder reactor and if their complex purification scheme for the fuel will work (both unlikely). Then they will have to apply to scale up and buiild new plants which take 9-19 years to build from the initial proposal. It will be at least 5+5+9 = 19 years before the first plants will be on-line in 2037. That is too late, we need a solution that we can build out today.
Abbott used the diagram of elemental abundance to show that the elements needed for nuclear reactors do not work. He included a table of how much of these metals are currently in production and current reserves which you did not address. This data showed that there are not enough materials for your nulcear utopia. Apparently Berylium is one of the key short materials. I mentioned it above but it appears to have slipped your memory.
India's "thorium reactor" includes uranium to burn the thorium. In 2013 it was scheduled to fire up in 2014. In 2014 in 2015, in 2015 2016, and last summer (2017) in early 2018. It has not fired up yet. Placing all your money on an untried technology that is years behind schedule and even in the best case will not be ready in time is not a very good plan. Not very convincing.
In any case, nuclear is completely uneconomic. Renewable energy is half the cost of nuclear.
If you cannot be bothered to find references to support your wild claims you should comment at anonther site where they do not care what absurd claims you make up.
nigelj,
Nuclear safety is much better than other fuel/energy producers. The difficulties are public perception of these accidents. for example the THTR reactor that used thorium uranium fuel mixture was shut down regarding an accident that released a small amount of radiation outside the building. This was following Chernobyl and with the Green lobby, the German Parliament it was used as a pretext to shut the building down. The designs are currently being used for a scaled up reactor in China. The article fails to mention that the reactor is capable of using thorium fuel.
https://www.technologyreview.com/s/600757/china-could-have-a-meltdown-proof-nuclear-reactor-next-year/
https://www.nextbigfuture.com/2014/04/construction-progresses-on-chinas-high.html
https://www.nextbigfuture.com/2017/04/china-has-started-loading-pebble-bed-fuel-into-new-reactor-which-will-begin-operation-later-this-year.html
Your point on contaminated land is probably the most pertinent, certainly in the west, as in order to maintain low radiological doses people are removed from the proximity of the leak, But you must remember that the biggest leak of artificial radiation occurred in the 1950s, 1960s during the bomb tests.
In the west the green lobbies are strong, but I do not hear much from these in places like China, Iran and Russia. They will carry on with their nuclear programs and ignore the West hesitation. There will not be problems with siting the reactors too close to population centres.
Unhampered by lack of energy resources these economies will grow and will get more powerful and so will be able to overshaow the West
. We are already seeing this in China which is becoming to dominate the far east and is busily influecing a lot of the countries in development inAfrica and South America. If the west do not thrive economically then the eastern block will overtake the western economies.
ps here is a reference to the use of Boron insted of Halfnium in nuclear reactors
https://www.bbc.co.uk/education/guides/zpp4jxs/revision/2
what it pinot out is that it is taught to 14 year olds in Britain was ignored in Abbott and the peer reviewers
http://fhr.nuc.berkeley.edu/wp-content/uploads/2014/10/12-007_Boron_Use_in_PWRs_and_FHRs.pdf
Alchymst,
Proposed theoretical reactors that have never been built are not solutions.
3 have been built 2 in Germany which the green lobby shut down and one in China (see refs in above post)
Abbott discusses the breeder reactors you propose.
No he does not he only dicusses liquid cooled reactors not gas cooled as I proposed
The fact that none have been able to run for significant amounts without problems tells us how likely it is that they will be useful in a reasonable amount of time.
The Julich demonstration reactor reactor ran for 20 years
Work out a timeline: if they have a design next week it will take them 5-10 years to build. Then it will take 5-10 years to determine if the alloys they have chosen can withstand the extreme conditions in the breeder reactor and if their complex purification scheme for the fuel will work (both unlikely).
China is loading the first reactor, 7 more are in various stages of construction on the site, see above post for reference
Then they will have to apply to scale up and buiild new plants which take 9-19 years to build from the initial proposal. It will be at least 5+5+9 = 19 years before the first plants will be on-line in 2037. That is too late, we need a solution that we can build out today.
see previos comment 1 is being loaded 7 more are in construction
Abbott used the diagram of elemental abundance to show that the elements needed for nuclear reactors do not work. He included a table of how much of these metals are currently in production and current reserves which you did not address.
Abbot for example used halfnium as a rare metal which was needed in a nuclear reactor. halfnium is used in submarines as cost is of litte object. Civilian reactors use Boron, Cadmium and silver for references see above. one of the references is for 14 year old schoolscience in the UK, so if children are expected to know this why the fuss about halfnium. The second ref is from the nuclear engineering department Berkley, California.
This data showed that there are not enough materials for your nulcear utopia. Apparently Berylium is one of the key short materials. I mentioned it above but it appears to have slipped your memory.
Beryllium is a reflector it is used for small reactors and for starters. It is not needed for large reactors. no reference but a bit of physics. Beryllium reflectors bounce back the neutrons into the reactor. For this to work the k infinity of the core material is greater than unity. If k infinity is greater than one then a sufficiently large reactor does not need a reflector, and does not need to infinite!
India's "thorium reactor" includes uranium to burn the thorium. In 2013 it was scheduled to fire up in 2014. In 2014 in 2015, in 2015 2016, and last summer (2017) in early 2018. It has not fired up yet. Placing all your money on an untried technology that is years behind schedule and even in the best case will not be ready in time is not a very good plan. Not very convincing.
The advanced heavy water reactor (AHWR) is one of the few proposed large-scale uses of thorium.[52] India is developing this technology, their interest motivated by substantial thorium reserves; almost a third of the world's thorium reserves are in India, which also lacks significant uranium reserves.
The third and final core of the Shippingport Atomic Power Station 60 MWe reactor was a light water thorium breeder, which began operating in 1977.[53] It used pellets made of thorium dioxide and uranium-233 oxide; initially, the U-233 content of the pellets was 5–6% in the seed region, 1.5–3% in the blanket region and none in the reflector region. It operated at 236 MWt, generating 60 MWe and ultimately produced over 2.1 billion kilowatt hours of electricity. After five years, the core was removed and found to contain nearly 1.4% more fissile material than when it was installed, demonstrating that breeding from thorium had occurred.[54][55]
https://en.wikipedia.org/wiki/Breeder_reactor
In any case, nuclear is completely uneconomic. Renewable energy is half the cost of nuclear.
If you cannot be bothered to find references to support your wild claims you should comment at anonther site where they do not care what absurd claims you make up.
Sweet please try and stop insulting peoples inteligence
Alchemyst @21
Right now nuclear is safer than other sources of electricity. I just wonder how the statistics will look if multiple third world countries have reactors. It wont take many accidents to radically change the statistics per mwhr.
But listen. I'm not firmly opposed to nuclear power in principle. I have always said its an individual countries choice on what suits them. I doubt nuclear will become prolific enough for my worst fears about safety to materialise, so Im not too worried over the issue.
I agree safety it is a public perception thing. But you can hardly blame people. Like I said, nuclear accidents are shocking, and have a sort of disproportionate effect on our consciousness. Its the same as the way some people respond to islamic terrorism, they go batshit crazy. In fact more people in the USA are killed by lawn mower accidents each year on average. But its the unpredictability of terrorism and its gruesome nature that scares people, and much the same can be said of nuclear accidents, because they are just so unpredictable, deadly and the contamination is both a real problem, and an insidious sort of thing psychologically.
However its hard changing human nature, and so on that basis I suggest the nuclear industry needs a "gamechanger" technology in terms of safety, something that really makes a fresh start. You can't blame the green lobby. The general public look at the issues for themselves.
You quote the example of China, and rapid progress with nuclear power. Ok fair enough. Obviously in a dictatorship they don't care about any public opposition like in the west. This is great for the nuclear industry, do you really want to live under a dictatorship? And this dictatorship has made a mess of their environment in other respects.
I also wonder how many safety shortcuts are made in China to build the reactors that fast.
Western countries are free market democracies. I like that on the whole. People have a right to protest and long may this remain. Safety standards are likely going to be better than China and if this slows down construction, "so be it".
Electricity generators in America for example make the choice of nuclear or wind power, and I think it should be left to them to make that choice. Do you think governments should force nuclear power on 1)the population, and 2) onto generating companies? Seems too draconian to me and not in line with western values.
Having said that, government has to ensure the electricity system is stable, and of course lines companies have to ensure stability of supply. NZ has legislation requiring generators provide adequate generation to cope with shortgages etc, so this forces the electricity companies to carefully consider all options. They will build nuclear - if they absolutely have to for stability of supply. But right now wind and solar are economically attractive options. But my point is this seems like a generally good overall framework of decision making, that balances a free market with the state ensuring there is fundamental stability of supply
Regarding Halfnium, I do not know enough to really comment. However I was reading an article the other day that the world only has 50 years of cobalt left (ok it will be more in reality, but you hopefully see the point). The point Im making is many minerals have limited reserves. If Nuclear expands radically, it seems a fair bet some of its metals requirements are going to get expensive. Of course lets be fair, this is not unique to the nuclear industry, but nuclear power uses a lot of specialist metals, and its another problem to add to an industry with problems.
Alchemyst is quite elogious on China's nuclear program. I looked into it a little to see if the usual problems were better dealt with (delays and cost overruns) and was not so impressed. Alchemyst refered to Wikipedia, so I'm taking it as an acceptable source of information.
The Wiki on China nuclear program reveals a mixed picture. The first 3 links in post 21 refers to the CAP 1400 reactors, an evolution of the Westinghouse AP1000 design, set to be built at the Shidawoan site. One link is from 2014, the other 2016, the last from 2017 mentions the scaled down version of the Westinghouse design. The current Shidawoan installation is a proof of concept demonstration project, which was set to be connected to the grid in 2018. That first unit is a 200 MW scaled down version of the full size 1400 MW design. The CAP1400 design passed the IAEA generic reactor safety review in 2015 and construction was set to begin by the end of that year. However, as of 2017, construction has been postponed because of the significant delays in completing the AP1000, Westinghouse older design. Westinghouse was majority owned by Toshiba but has filed for bankruptcy, which could be a major hurdle in bringing the CAP1400 design into existence. My take is that enthusiasm for the AP1400 should wait at least until construction is well under way and we're nowhere close to that.
The problems with nuclear energy remain: it is extremely expensive, usually more than planned; construction takes a long time, once again usually more than planned. Plants have a limited life span, beyond 40-50 years the upkeep adds significant costs to production.
The CANDU (pressurized heavy water reactors pioneered in Canada) types of plants look like a good idea in theory, especially from the operational safety point of view, although tritium emissions need attention. The fact that they can draw from a variety of fue sources and recovered uranium also speaks in their favor. The CANDU6 reactors built in Quinshan can boast of their completion on schedule and on budget, refreshing among modern built facilities. Most such reactors are found in Ontario, and many have been decommissioned, sometimes at very high costs. Economic performance does not call for more enthusiasm than the yet-to-be-started AP1400. From the CANDU wiki:
"Based on Ontario's record, the economic performance of the CANDU system is quite poor.[according to whom?] Although much attention has been focussed on the problems with the Darlington plant, every CANDU design in Ontario went over budget by at least 25%, and average over 150% higher than estimated.[66] Darlington was the worst, at 350% over budget, but this project was stopped in-progress thereby incurring additional interest charges during a period of high interest rates, which is a special situation that was not expected to repeat itself."
Furthermore: "In 1998, Ontario Hydro calculated that the cost of generation from CANDU was 7.7 cents/kWh, whereas hydropower was only 1.1 cents, and their coal-fired plants were 4.3 cents. As Ontario Hydro received a regulated price averaging 6.3 cents/kWh for power in this period, the revenues from the other forms of generation were being used to fund the operating losses of the nuclear plants."
Nuclear is no panacea and does not deserve less careful consideration than any other solution.
Alchymist,
I see others have responded to most of your wild, unsupported claims. I will address only your unsupported assertion that nuclear can compete with renewable energy.
According to many news reports:
"On a Q4 earnings conference call on Friday, Robo [CEO of NextEra Energy] predicted that by the early 2020s, it will be cheaper to build new renewables than to continue running existing coal and nuclear plants" my emphasis.
Since capitol costs are so high for nuclear plants they are already more expensive than renewable energy. The builds at Georgia and South Carolina were supposed to prove that the nuclear industry could build on time and on budget. Two reactors have been abandoned half finished and far over budget. Westinghouse, the primary contractor, is bankrupt and the remaining build is near abandonment, way over budget and years behind schedule.
Renewables are the way of the future.
Dear sweet,
please could you point out where I said that nuclear can compete with renewables.
I have not stated it.
Alchymist,
Apparently I misread your post because you said "Sweet please try and stop insulting peoples inteligence" immediately after quoting me saying nuclear was much more expensive than renewable energy.
I am glad that we agree that nuclear energy cannot compete economically with renewable energy.
I note that you have provided no references that address Abbotts peer reviewed claims that not enough rare elements exist to build out nuclear power. None of your citations say how much of any metals are required to build the reactors you support. I have provided a reference to prove that enough materials exist to build out all needed renewable energy systems. Abbotts conclusion stands unchallenged.
Serious energy researchers do not consider significant amounts of nuclear energy in the mix in the future. In Smart Energy Europe (cited at least 75 times in less than 2 years from publication) the first of 9 steps to convert to full renewable energy is to remove nuclear energy from the system.
I note that none of your citations is peer reviewed.
Sweet you are trolling
I have shown that Abbott is using whie swan arguments in his paper.
for example he quotes liitations on nuclear materials citing Halfnium.
I quote your post 13 feb 3:16 am
"not enough rare elements like hafnium exist,"
How halfnium is hardly ever used in civilian reactors. So abundance linits does not pose a limitation on nuclear reactor build.
Boron is the prefered material, and there is no shortage of Boron in the world. this is taught to 14 year old schoolchildren in the UK
http://www.bbc.co.uk/bitesize/intermediate2/physics/radioactivity/nuclear_power_stations/revision/2/
You are trolling.
For those interested see below. Howeve Sweet you are trolling, most people have been into the argument on one side or the other, but you even when your statment has been shown to be without basis
My references in the earler post to nigelj, you now state
"note that you have provided no references that address Abbotts peer reviewed claims that not enough rare elements exist to build out nuclear power. None of your citations say how much of any metals are required to build the reactors you support. I have provided a reference to prove that enough materials exist to build out all needed renewable energy systems. Abbotts conclusion stands unchallenged."
I pass you onto Wikipedia where the status of Halfnium in civilian reactors is stated that it is hardly ever used and other materials are prefered.
https://en.wikipedia.org/wiki/Control_rod
Control rods are used in nuclear reactors to control the fission rate of uranium and plutonium. They are composed of chemical elements such as boron, silver, indium and cadmium that are capable of absorbing many neutrons without themselves fissioning. Because these elements have different capture cross sections for neutrons of varying energies, the composition of the control rods must be designed for the reactor's neutron spectrum. Boiling water reactors (BWR), pressurized water reactors (PWR) and heavy water reactors (HWR) operate with thermal neutrons, while breeder reactors operate with fast neutrons.
Halfnium has excellent properties for reactors using water for both moderation and cooling. It has good mechanical strength, can be easily fabricated, and is resistant to corrosion in hot water.[9] Hafnium can be alloyed with other elements, e.g. with tin and oxygen to increase tensile and creep strength, with iron, chromium and niobium for corrosion resistance, and with molybdenum for wear resistance, hardness and machineability. Such alloys are designated as Hafaloy, Hafaloy-M, Hafaloy-N, and Hafaloy-NM.[10] The high cost and low availability of hafnium limit its use in civilian reactors, although it is used in some US Navy reactors. Hafnium carbide can also be used as an insoluble material with a high melting point of 3890 °C and density higher than that of uranium dioxide for sinking unmelted through corium.
[JH] Given that your discorse with Michael Sweet has devolved into name calling and given that you are now engaging in excessive repitition, it is time to shut down this discussion. Your future posts on this topic will be summarily deleted.
Please note that posting comments here at SkS is a privilege, not a right. This privilege can and will be rescinded if the posting individual continues to treat adherence to the Comments Policy as optional, rather than the mandatory condition of participating in this online forum.
Moderating this site is a tiresome chore, particularly when commentators repeatedly submit offensive, off-topic posts or intentionally misleading comments and graphics or simply make things up. We really appreciate people's cooperation in abiding by the Comments Policy, which is largely responsible for the quality of this site.
Finally, please understand that moderation policies are not open for discussion. If you find yourself incapable of abiding by these common set of rules that everyone else observes, then a change of venues is in the offing.
Please take the time to review the policy and ensure future comments are in full compliance with it. Thanks for your understanding and compliance in this matter, as no further warnings shall be given.
Alchymist,
I must inform you that the BBC and Wikipedia are not peer reviewed sources. You have provided no peer reviewed data to support your claims. Abbott is peer reviewed. Your BBC link is for school children. It does not give the full formulation of the conntrol rods. Boron cannot be fashioned into rods by itself. It must be mixed with and coated by other exotic materials to form the control rods. You must account for all the materials put into the plant, not just a few of them.
The breeder reactors you support are run at extremely high temperatures with extreme neutron fluxes. All the piping, valves,fuel rods and the container vessel must be made of exotic metals and alloys to withstand the extreme conditions. We have only the unsupported word of an anonymous person on the internet that all these materials exist against the peer reviewed study of Abbott, who is an expert in the field, that they do not exist. You have provided no information to determine if the metals in the valves, piping and container are in sufficient supply to build. We have only your personal assertion that the control rods can be manufactured.
You are repeating yourself without providing supporting data. That is sloganeering. You have provided no peer reviewed data to support your claims, that is trolling.
[PS] It is time to wrap this discussion. This site is not a good forum for discussions of pros and cons of nuclear power (BraveNewClimate did that better) and it is offtopic for this thread. If we had a thread based on peer-reviewed literature concerning nuclear power, then the science could be discussed there but so far we have not been able to find an author to write one. Volunteers welcome.
I don't have remotely enough knowledge of nuclear power technology to write an article. But Alchemyst, it appears you or anyone else are being given a golden opportunity here to submit something.
I would just suggest an article needs to obviously be based on verifiable credible source material, with internet links, and should mention within the body of the article the problems as well as the benefits of nuclear, and in a full, open way. If it doesn't, it will be cut to pieces by readers, and called one sided. If its an article that is open and transparent, it may serve some useful purpose. I don't care if the tone of the article is negative or positive on the issue, as long as its upfront like this.
But IMHO the writer is perfectly entitled to reach their conclusions firmly for or against nuclear power and as strongly as they wish, and is not expected to sit on the fence.
I remain a bit sceptical of nuclear power, but hopefully not closed minded.
[PS] No more please. Continued offtopic posts will be deleted.
Moderator
I was disappointed to get to the end of this post only to find that further discussion had been terminated. I was hoping to challenge Alchemyst to read a fascinating debate that took place on the curryetc website based upon a recent paper by Peter Lang. Lang's questionable premise is that the "root cause" of the demise of the nuclear industry in the US were anti-nuke protesters which caused over regulation. The paper is found in the December 2017 topics on the curry website. I had been spending my time reading all 256 posts on that website before I commented here.
However, Lang did not anticipate that someone with over 35 years experiencer in managing construction of nuclear plants in the US would take him on. He goes by the name Beta Blocker for reasons explained in the blog. His basic premise is that the poor managment processes of Westinghouse and others were largely to blame for the massive cost overruns which really sunk the industry and provided the fodder for the smarter nuclear protesters who appeared at hearings.
My suggestion to respond to the suggestion of michael sweet was going to propose that you let Peter Lang publish his paper on this website and let others take a run at him. I understand that there has been some "history" with Lang on this website which might complicate my suggestion. Lang does not do well against Beta Blocker.
There was one other commenter on that blog who was very knowledgeable called Ristvan. His view in a nutshell is that concrete and steel sunk the nuclear industry.
But the "supply" issue of nuclear sources suggested by Abbott does not seem to be the real issue given that the new nuclear reactors will use 99% rather than 1% of the energy in uranium. Beta Blocker is clearly retired now but is in communication with those active in the industry. I get the sense that Small Modular Reactors do show promise. He also deals with storage issues.
I undertstand that this post may not see the light of day but I wanted to support michael sweet's suggestion of a paper on this topic.
I believe you have my email as part of registration on this website if you want to reply without posting.