






























 Arguments
Arguments





















Why Curry, McIntyre, and Co. are Still Wrong about IPCC Climate Model Accuracy
Posted on 4 October 2013 by dana1981
Earlier this week, I explained why IPCC model global warming projections have done much better than you think. Given the popularity of the Models are unreliable myth (coming in at #6 on the list of most used climate myths), it's not surprising that the post met with substantial resistance from climate contrarians, particularly in the comments on its Guardian cross-post. Many of the commenters referenced a blog post published on the same day by blogger Steve McIntyre.
McIntyre is puzzled as to why the depiction of the climate model projections and observational data shifted between the draft and draft final versions (the AR5 report won't be final until approximately January 2014) of Figure 1.4 in the IPCC AR5 report. The draft and draft final versions are illustrated side-by-side below.
I explained the reason behind the change in my post. It's due to the fact that, as statistician and blogger Tamino noted 10 months ago when the draft was "leaked," the draft figure was improperly baselined.
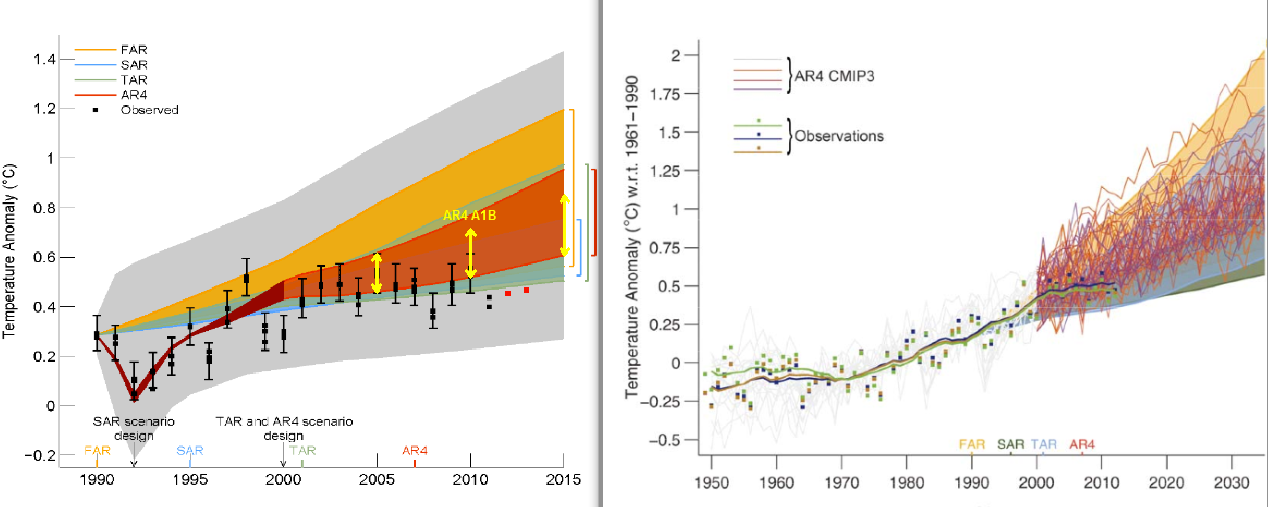
IPCC AR5 Figure 1.4 draft (left) and draft final (right) versions. In the draft final version, solid lines and squares represent measured average global surface temperature changes by NASA (blue), NOAA (yellow), and the UK Hadley Centre (green). The colored shading shows the projected range of surface warming in the IPCC First Assessment Report (FAR; yellow), Second (SAR; green), Third (TAR; blue), and Fourth (AR4; red).
What's Baselining and Why is it Important?
Global mean surface temperature data are plotted not in absolute temperatures, but rather as anomalies, which are the difference between each data point and some reference temperature. That reference temperature is determined by the 'baseline' period; for example, if we want to compare today's temperatures to those during the mid to late 20th century, our baseline period might be 1961–1990. For global surface temperatures, the baseline is usually calculated over a 30-year period in order to accurately reflect any long-term trends rather than being biased by short-term noise.
It appears that the draft version of Figure 1.4 did not use a 30-year baseline, but rather aligned the models and data to match at the year 1990. How do we know this is the case? Up to that date, 1990 was the hottest year on record, and remained the hottest on record until 1995. At the time, 1990 was an especially hot year. Consequently, if the models and data were properly baselined, the 1990 data point would be located toward the high end of the range of model simulations. In the draft IPCC figure, that wasn't the case – the models and data matched exactly in 1990, suggesting that they were likely baselined using just a single year.
Mistakes happen, especially in draft documents, and the IPCC report contributors subsequently corrected the error, now using 1961–1990 as the baseline. But Steve McIntyre just couldn't seem to figure out why the data were shifted between the draft and draft final versions, even though Tamino had pointed out that the figure should be corrected 10 months prior. How did McIntyre explain the change?
"The scale of the Second Draft showed the discrepancy between models and observations much more clearly. I do not believe that IPCC’s decision to use a more obscure scale was accidental."
No, it wasn't accidental. It was a correction of a rather obvious error in the draft figure. It's an important correction because improper baselining can make a graph visually deceiving, as was the case in the draft version of Figure 1.4.
Curry Chimes in – 'McIntyre Said So'
The fact that McIntyre failed to identify the baselining correction is itself not a big deal, although it doesn't reflect well on his math or analytical abilities. The fact that he defaulted to an implication of a conspiracy theory rather than actually doing any data analysis doesn't reflect particularly well on his analytical mindset, but a blogger is free to say what he likes on his blog.
The problem lies in the significant number of people who continued to believe that the modeled global surface temperature projections in the IPCC reports were inaccurate – despite my having shown they have been accurate and having explained the error in the draft figure – for no other reason than 'McIntyre said so.' This appeal to McIntyre's supposed authority extended to Judith Curry on Twitter, who asserted with a link to McIntyre's blog, in response to my post,
"No the models are still wrong, in spite of IPCC attempts to mislead."
In short, Curry seems to agree with McIntyre's conspiratorial implication that the IPCC had shifted the data in the figure because they were attempting to mislead the public. What was Curry's evidence for this accusation? She expanded on her blog.
"Steve McIntyre has a post IPCC: Fixing the Facts that discusses the metamorphosis of the two versions of Figure 1.4 ... Using different choices for this can be superficially misleading, but doesn’t really obscure the underlying important point, which is summarized by Ross McKitrick on the ClimateAudit thread"
Ross McKitrick (an economist and climate contrarian), it turns out, had also offered his opinion about Figure 1.4, with the same lack of analysis as McIntyre's (emphasis added).
"Playing with the starting value only determines whether the models and observations will appear to agree best in the early, middle or late portion of the graph. It doesn’t affect the discrepancy of trends, which is the main issue here. The trend discrepancy was quite visible in the 2nd draft Figure 1.4."
In short, Curry deferred to McIntyre's and McKitrick's "gut feelings." This is perhaps not surprising, since she has previously described the duo in glowing terms:
"Mr. McIntyre, unfortunately for his opponents, happens to combine mathematical genius with a Terminator-like relentlessness. He also found a brilliant partner in Ross McKitrick, an economics professor at the University of Guelph.
Brilliant or not, neither produced a shred of analysis or evidence to support his conspiratorial hypothesis.
Do as McKitrick Says, not as he Doesn't Do – Check the Trends
In his comment, McKitrick actually touched on the solution to the problem. Look at the trends! The trend is essentially the slope of the data, which is unaffected by the choice of baseline.
Unfortunately, McKitrick was satisfied to try and eyeball the trends in the draft version of Figure 1.4 rather than actually calculate them. That's a big no-no. Scientists don't rely on their senses for a reason – our senses can easily deceive us.
So what happens if we actually analyze the trends in both the observational data and model simulations? That's what I did in my original blog post. Tamino has helpfully compared the modeled and observed trends in the figure below.
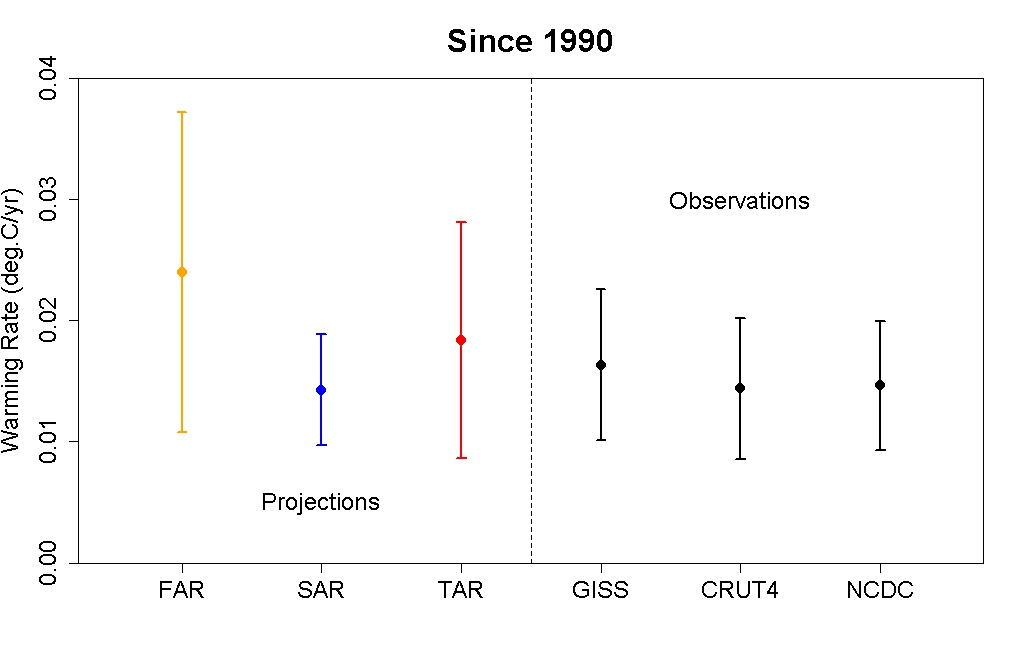
Global mean surface temperature warming rates and uncertainty ranges for 1990–2012 based on model projections used in the IPCC First Assessment Report (FAR; yellow), Second (SAR; blue), and Third (TAR; red) as compared to observational data (black). Created by Tamino.
The observed trends are entirely consistent with the projections made by the climate models in each IPCC report. Note that the warming trends are the same for both the draft and draft final versions of Figure 1.4 (I digitized the graphs and checked). The only difference in the data is the change in baselining.
This indicates that the draft final version of Figure 1.4 is more accurate, since consistent with the trends, the observational data falls within the model envelope.
Asking the Wrong (Cherry Picked) Question
Unlike weather models, climate models actually do better predicting climate changes several decades into the future, during which time the short-term fluctuations average out. Curry actually acknowledges this point.
This is good news, because with human-caused climate change, it's these long-term changes we're predominantly worried about. Unfortunately, Curry has a laser-like focus on the past 15 years.
"What is wrong is the failure of the IPCC to note the failure of nearly all climate model simulations to reproduce a pause of 15+ years."
This is an odd statement, given that Curry had earlier quoted the IPCC discussing this issue prominently in its Summary for Policymakers:
"Models do not generally reproduce the observed reduction in surface warming trend over the last 10 –15 years."
The observed trend for the period 1998–2012 is lower than most model simulations. But the observed trend for the period 1992–2006 is higher than most model simulations. Why weren't Curry and McIntyre decrying the models for underestimating global warming 6 years ago?
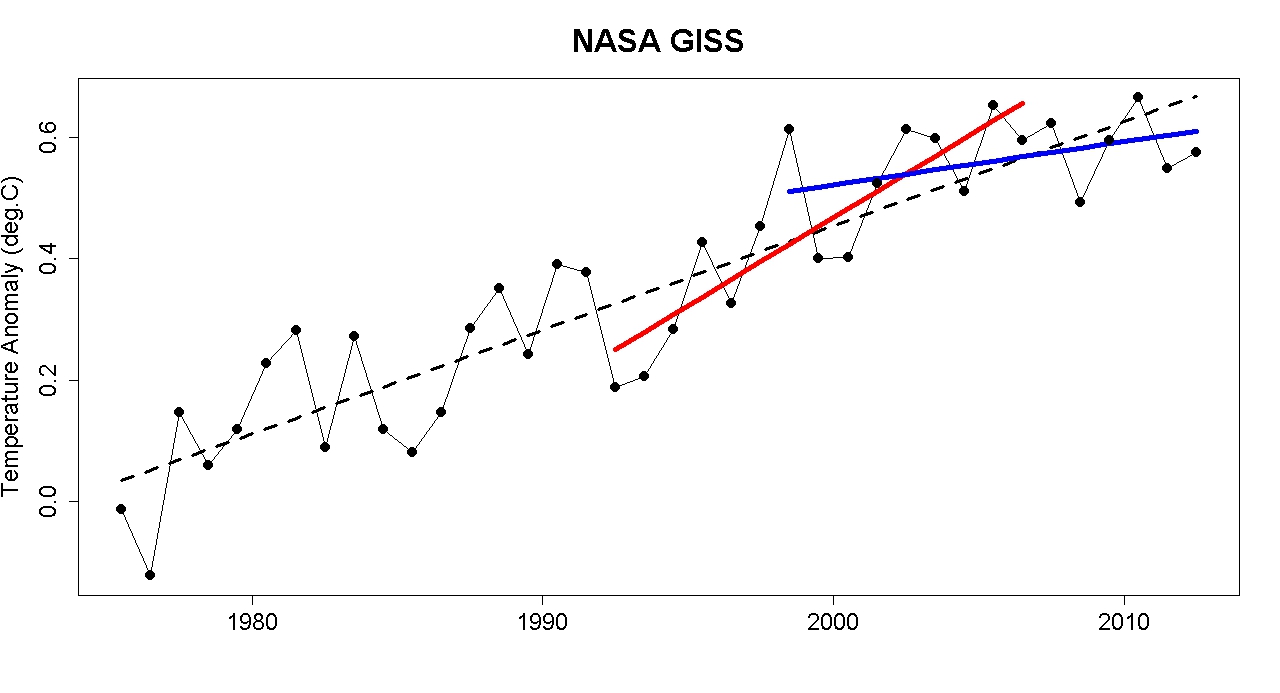
Global surface temperature data 1975–2012 from NASA with a linear trend (black), with trends for 1992–2006 (red) and 1998–2012 (blue). Created by Tamino.
This suggests that perhaps climate models underestimate the magnitude of the climate's short-term internal variability. Curry believes this is a critical point that justifies her conclusion "climate models are just as bad as we thought." But as the IPCC notes, the internal variability on which Curry focuses averages out over time.
"The contribution [to the 1951–2010 global surface warming trend] ... from internal variability is likely to be in the range of −0.1°C to 0.1°C."
While it would be nice to be able to predict ocean cycles in advance and better reproduce short-term climate changes, we're much more interested in long-term changes, which are dominated by human greenhouse gas emissions. And which, as Curry admits, climate models do a good job simulating.
It's also worth looking back at what climate scientists were saying about the rapid short-term warming trend in 2007. Rahmstorf et al. (2007), for example, said (emphasis added):
"The global mean surface temperature increase (land and ocean combined) in both the NASA GISS data set and the Hadley Centre/Climatic Research Unit data set is 0.33°C for the 16 years since 1990, which is in the upper part of the range projected by the IPCC ... The first candidate reason is intrinsic variability within the climate system."
Data vs. Guts
Curry and Co. deferred to McIntyre and McKitrick's gut feelings about Figure 1.4, and both of their guts were wrong. Curry has also defaulted to her gut feeling on issues like global warming attribution, climate risk management, and climate science uncertainties. Despite her lack of expertise on these subjects, she is often interviewed about them by journalists seeking to "balance" their articles with a "skeptic" perspective.
Here at Skeptical Science, we don't ask our readers to rely on our gut feelings. We strive to base all of our blog posts and myth rebuttals on peer-reviewed research and/or empirical data analysis. Curry, McIntyre, and McKitrick have failed to do the same.
When there's a conflict between two sides where one is based on empirical data, and the other is based on "Curry and McIntyre say so," the correct answer should be clear. The global climate models used by the IPCC have done a good job projecting the global mean surface temperature change since 1990.









I'll answer your question, but then please answer mine.
I'll take Tom's CMIP3 trends at face value (He has a stellar reputation after all). However, you'll note that those trends are for differring lengths of time, and not what the IPCC has based their predictions on.In fact,only one of them is longer than 30 years. This is apples and oranges.
What is the min temp increase rate predicted in AR4? Is it 0.10 C / Decade, or is it 0.15 C /Decade?
The answer has a large impact on Tom's trend graph.
Dikran Marsupial,
Yes, I accept that Tom presented the CIMP3 trends accurately. But that is apples to oranges. Only one of those trends is over 30 years long. The question that I am asking has to do with the minimum expected temperature increase rate predicted in AR4. Is it 0.10 C/ Decade as Tom depicted in his trend graph (and Dana1981 in his "better than you think" post), or is it 0.15 C /Decade as I maintain? The answer has a large impact on the graph presentative that Tom did on trends in @79.
frankefkin Thank you. It was important that you agree that Tom's representation of the CMIP3 models was essentially correct, becase the answer to your question is that the IPCC report was written in 2006/7, and they didn't anticipate absolutely every question that could be asked (including specifications of the level of confidence), so the report itself doesn't give direct answers to every single question. So if none of the answers matches the question you want to ask sufficiently closely, you have to go back to the CMIP3 models, on which the AR4 WG1 projections are made. Which is just what Tom did.
Now it appears that you do not understand some of the subtleties in the figures given in the reports (for instance that decadal warming rates given for centennial scale projections will be an over-estimate of the warming for the present decade, or that a "likely" range will not include the "minimum"). In interpreting the IPCC report you need to pay close attention to what is actually written and understand the limitations that places on the inferences you can draw.
The "apples and oranges" things is exactly the point, the figures that you have been quoting from the IPCC report are "apples" when compared with observed trends over the last decade or so ("oranges"). Fortunately the IPCC made a publicly accessible archive of the model runs, so there is nothing to stop you from going to the archive and finding out the answers to your exact question.
Dikran Marsupial,
The IPCC in AR4 made projections as to what temperature increases it expected. You have alread indicated that you did not believe that 0.15 C/decade was the appropriate minimum, that you thought it was a leftover from FAR.
What was the minimum value that this increase was expected to be?
franklefkin It has already been pointed out to you several times that the figures you have quoted are not representative of the range of trends the IPCC would consider plausible for recent decades. If you are not going to pay attention when the errors in your reasoning are pointed out, there is very little chance of any progress being made in this discussion.
If you want to know what the minimum value was expected to see, download the model runs from the CMIP3 archive and find out, because it is unreasonable to expect every possible permutation of every question to be explicitly answered in the report.
Perhaps it would help if you were to specify exactly the trend you are interested in (start and end date, and the level of uncertainty for the range of values).
franklefkin - Over what period? As has been pointed out, given the expectation of faster warming over the next century or so under most emission scenarios, warming over the next few decades will be less than warming at the end of the 21st century.
And, given natural variability of the climate, it is entirely to be expected that observations will vary widely as per the CMIP3 and CMIP5 projected boundaries. Climate projections are a boundary problem, not a detailed initial value problem, and describe what the long term mean of the weather will be given the physics and various emissions scenarios. Past variability from ENSO, volcanic activity, and basic weather will continue to take observations both above and below the mean of the the most accurate model projections - and those short term variations by no means disprove the science.
Tom Dayton @ 86. Agreed, responders here tend to get a bit carried away with long-winded complex comments that are lost upon many readers. The beauty of that particular image is that it immediately cuts through all the technobabble. Readers can immediately see an apples-to-apples comparison, and realize that contrarians are trying to pull the wool over their eyes.
May have to write a post/rebuttal based upon it - given that this myth is one of the most common of late.
Dikran,
I believe that you are not understanding something. I was quoting the IPCC in AR4. I am not looking for a specific CMIP3 trend. Since you told me I was incorrect about what the IPCC had projected in AR4, I am simply asking you what they had projected. Surely since you know I was wrong, even though I quoted them directly, you know what the answer is.
I answerred your question, please answer mine.
franklefkin Says "I am not looking for a specific CMIP3 trend". O.K., but in that case, you are restricted to using the figures in the report exactly according to their stated meaning, in this case average rates of warming over the course of a century. In that case, you can't use them for comparison with the observations until we have observations for the whole century and you can do an "apples versus apples" comparison.
If you want to do a comparison with the observations over some arbitrary interval (as discussed in the main article), an explicit answer is not given in the reports and you need to go back to the CMIP3 model runs to get an "apples versus apples" comparison.
Your question has been answered, the problem is that you don't appear to know exactly what the question is, and you appear unable to accept that you have not appreciated what the figures in the report that you have quoted actually mean.
Dikran Marsupial,
This is taken directly from AR4;
In the subsequent paragraph (both this one and the next I have already posted here) it goes on to state the this 0.20 C /decade is bounded by 0.10 and 0.30 C. So it is not I who is taking anything out of context. AR4 made the projection. In his post at 79, Tom Curtis compares actual temps with a minimum trend of 0.10 C /decade in an attempt to show how accurate the models' projections have been. To be accurate, I am saying that a minimum value of 0.15 C/decade should be used. When it is, the models' accuracy at projections does not look as good!
The words are not mine, they came from the IPCC in AR4.
So where did the value of 0.10 c /Decade come from?
Dikran,
Another thought. Perhaps the route you are suggesting is correct. If that is the case, why would the IPCC use the wrong ranges in AR4?
franklefkin in varius comments has presented two quotes from the IPCC. The first is from the technical summary of WG1, while the second was from the Synthesis report.
The first reads (properly formatted):
"A major advance of this assessment of climate change projections compared with the TAR is the large number of simulations available from a broader range of models. Taken together with additional information from observations, these provide a quantitative basis for estimating likelihoods for many aspects of future climate change. Model simulations cover a range of possible futures including idealised emission or concentration assumptions. These include SRES[14] illustrative marker scenarios for the 2000 to 2100 period and model experiments with greenhouse gases and aerosol concentrations held constant after year 2000 or 2100.
(Original formating and emphasis.)
Since originally quoteing this test, franklefkin has quoted the third seperately, describing it as "a further quote". He has then gone on to quote the second paragraph seperately, saying "This is taken directly from IPCC AR4", and going on to mention the contents of the third paragraph.
Curiously, when franklefkin quoted the third paragraph seperately, he describes it as referring to prior assessement reports, saying:
In contrast, on the other two times he quotes or mentions this paragraph, he takes it as referring to the IPCC AR4 projections. Thus he has contradictory interpretations of the same passage.
For what it is worth, I agree with the interpretation that this refers to past assessment reports (first given by Dikran Marsupial in this discussion). That interpretation makes the most sense of the chosen trend period, which starts with the first projected year in all prior reports, and ends in the last full year of data when AR4 was being reported. In contrast, AR4 strictly does not project from 1990 but from 2000 (up to which time they have historical data for forcings).
It is possible, however, to interpret this as further qualifying the AR4 projection. That is an unlikely interpretation given the clear seperation into a distinct paragraph within the IPCC report, but it is possible. On that interpretation, however, it probably follows IPCC custom in refering to the "likely" range of temperatures, ie, the 17th to 83rd percentiles. Here then are the likely range for the trends I have reported from CMIP3:
_____________17.00%_83.00%
1975-2015:__0.149__0.256
1990-2015:__0.157__0.339
1992-2006:__0.128__0.470
1990-2005:__0.136__0.421
Note that the likely range from 0.136 to 0.421trend over the same period of time reffered to in the quote.
The IPCC used only one run per model in its report, wheras I downloaded the full ensemble. It is possible, therefore, that the upper bound in the restricted ensemble used in AR4 is closer to three. The lower bound is sufficiently close to 1.5 as to create no issue. On this basis, reference to a "likely" range of 0.15-3 C for the 1990-2005 trend is consistent. It is also irrelevant. It would be extraordinary if the missing ensemble members would shrink the 0 to 100th percentile range (Min to Max) that I showed as much as franklefkin desires, and I have already quoted a more restricted 25th percentile greater model trends, showing continuing harping on the 17th percentile to be odd.
With respect to his second quote, as already pointed out, AR4 projections to the end of the century are not linear, and hence not simply interpretable as projections over the early decades of the twenty first century:
Finally, the only clear projection for the first decades of the twenty first century by AR4 is 0.2 C per decade. In my graph I show the ensemble mean trend 0.237 C/decade. So, while I have accurately reported, if anything my graph exagerates the "failings" of observations rather than the reverse.
I see little further point in responding to franklefkin on this point as he is getting repetitive (to say the least). Further, he is neither consistent, nor willing to concede the most straight forward points (such as that trends sited for temperature rise over a century are not the same as projections for the first few decades of that century).
Hi Tom,
That is very clear, thank you. Could you please comment on your table, though, which refers to trends that extend to 2015:
_____________17.00%_83.00%
1975-2015:__0.149__0.256
1990-2015:__0.157__0.339
1992-2006:__0.128__0.470
1990-2005:__0.136__0.421
Is the "2015" a typo? If so, could the mods please edit the post to fix it (no point getting distracted over typos). If not, how were trends derived for years in the future?
Leto,
The table is referring to trends in the CMIP3 models, not the actual temperature record, therefore future dates are not a problem.
Going back to Tom's trend graph @ 79, and the attempts to argue that the actual temperature record is in some way inconsistent with the forecasts, I'd just like to point out that while the range of model trends is plotted, the actual temperature trends plotted do not include their ranges!
A quick check on the SkS trend calculator shows HadCRUT4 to be 0.140 ±0.077 °C/decade (2σ) and GISS to be 0.152 ±0.080 °C/decade (2σ). What that means is that there is a ~95% chance that the actual HadCRUT4 trend for 1990 to the present is somewhere between 0.063 and 0.217 °C/decade. There's a lot of overlap between the range of model projections and the range of possible actual trends.
For someone to argue that the models had failed to predict the actual temperature trend, these two ranges would need to have very little overlap indeed.
I should out that the second figure in the OP, from Tamino, captures this point perfectly. It includes the uncertainty ranges of both the various model forecasts and the actual records. Anybody arguing that the models have done a bad job is essentially saying that the overlaps between those two groups are so low that we can dismiss the models as unskillful (and therefore ignore what they project future consequences to be and continue BAU).
leto @113, I originally downloaded the data to check on AR4 with respect to the second graph in the original post, and on issues relating to the comparison between Fig 1.4 in the second order and final drafts of AR5. As I am manipulating the data on a spreadsheet, I decided to follow the 2nd order draft and limit the data to 2015, that being all that is necessary for the comparison. Consequently, model trends are to 2015 unless otherwise stated. Observed trends are to current using the SkS trend calculator unless otherwise stated.
Jason B's point about uncertainty ranges of observations is quite correct, but unfortunately I have yet to find a convenient means to show uncertainty ranges conveniently on Open Office Calc graphs without excessive clutter.
I have updated my chart to show min/max model boundary conditions. Basically, this is the same chart as Tom Curtis has drawn @88, except I continue to show the raw monthly HADCRUT4 temperature data and a 5-year center moving average. IMO, there is more meaningful information in all the data as opposed to showing simple trend lines for GISS and HADCRUT4. Depending on how the trends are selected the data can be skewed. Tom’s chart @88 shows HADCRUT4 and GISS trends as being between the CMIP3 mean and min values, whereas my chart shows the actual temperature as pushing the limits of the lower boundary conditions. Please examine the data closely: look at the temperature data, the point of origin of the CMIP3 min/max points, and the slopes of the lines. They all match Tom’s data. But I have more information and it leads to a slightly different conclusion, I think.
Dana goes to great length to attempt to explain that the left draft chart was a mistake due to baselining issues. My chart of the raw temperature data and Tom’s min/max model looks very similar to the draft IPCC chart. I doubt the people developing the draft chart made a major baseline mistake as claimed by Dana. If you look hard that the final IPCC chart, is does look similar to the draft chart, except that the scale is zoomed way out making the interesting area very small, and then they splattered spaghetti lines all over it. I can see why the skeptic crowd went nuts over the final IPCC chart.
A larger verison of this chart is here.
Several people have suggested that the first graph in post 79 may be useful for a post. Thanks. Several decisions should be made if it is to be so used. First, I have used the full ensemble rather than just one per model as is used by AR4. This may lead to accusations of deliberate cluttering as a cheat, so, if the post authors want to use the graph, do they want a new version with just one member per model? Further, in such a new graph, would they also like? the 2.5th and 97.5th (or 5th and 95th) percentiles marked as well as the minimum and maximum on the inset? Further, currently if you know what you are looking for you can pick out the observed data because:
a) They are the two top most lines, and hence are never overlaid by model runs;
b) They end in 2012; and
c) They track each other closely (unlike all other model runs) making it possible to distinguish them easily if you look closely, and know what you are looking for.
Do you want just one observed temperature series to obviate (c) above?
And finally, do you want a similar graph for AR5?
If the authors can answer the questions fairly promptly, I can get the graphs done up by this weekend. On the other hand, if you are happy with what is currently available you are more than welcome to use it as is (or to not use it, if that is your preference).
Opps. Moderator, the URL for larger image @117 is:
http://tinypic.com/r/5c105z/5
Thanks Tom and Jason B.
Thats sounds perfectly reasonable.
I presume the conclusions do not materially differ if 2013 is used as the endpoint for both models and observations? The comparison might be neater, though, with all the talk on both sides of apples and oranges.
Of course, it is a shame that such an important issue gets bogged down in minutiae in the first place, so it is with regret that I raise such trivia. Thinking defensively, though, there may be advantages in using 2013 in such a table.
Tom @ 118,
The 2.5th and 97.5th centiles would be of interest, given the traditional (but arbitrary) interest in the central 95% of a spread of values.
SAM, there are several problems with your graph as is.
The largest problem is that you do not show the observed trend. If you are showing the natural variation of the data, you should also show the variation in the models for a fair comparison, ie, something like the inset of my graph @79. Alternatively, if you want to compare trends, compare trends!
If you also want to show the actual data, that is fine. The way I would do it would be to show the actual 1990-2013 trend for the data, properly baselined (ie, baselined over the 1990-2013 interval. I would then show the range and mean (or median) of the model trends baselined to have a common origin with the observed trend in 1990.
Doing this would ofset the origins of the trend comparison from the temperature series. That has the advantage of making it clear that you are comparing trend lines; and that the model trend lines shown are not the expected range of observed temperatures. Ie, it would get rid of most of the misleading features of the graph.
You may also want to plot the 2.5th to 97.5th percentiles (or min to max) of the model realizations set with a common 20-30 year baseline (either 1961-1990, or 1981-2000) to allow comparison with the expected variation of the data on the same graph. That may make the graph a little cluttered, but would allow comparison with both relevant features of the model/observation comparison.
As is, you do not compare both. Rather you compare one relevant feature of observations with the other relevant feature of models; and as a result allow neither relevant feature to actually be compared.
SASM @ 117,
Basically, this is the same chart as Tom Curtis has drawn @88, except I continue to show the raw monthly HADCRUT4 temperature data and a 5-year center moving average.
No, it's not. Tom's chart draws trendlines only. As a consequence, there is no initial value problem and all trend lines can safely start at the same point.
You show actual temperature anomalies and compare them with trendlines. This has two problems:
1. You anchor the trendlines to start the on the 5-year centred moving average temperature in 1990. If you really want to go down this path and you want to do it "properly", then you should use a much longer average than 5 years. Given that climate is commonly defined to be the average of 30 years, you should use the 30-year centred moving average at 1990. By my calculation that would drop the starting point by 0.04 C, making a big difference to the appearance of your chart.
2. More importantly, comparing monthly data with straight trendlines will naturally show periods where the monthly data (and even smoothed data) goes outside those trendlines, even when those trandlines are minimum and maximum trend lines. That's because they're the minimum and maximum range for the trend, not the minimum and maximum values for the monthly figures at any point in time! Plot the trend line for HadCRUT starting at the same point and ending today. Does it lie well within the minimum and maximum trend lines? Obviously it must, this is what Tom showed. Include the range of uncertainty for the trend itself. What is the likelihood that the true trend does not lie within the minimum and maximum range forecast? As a bonus, if you include the range of uncertainty for the trend itself then you can generate shorter and shorter trends for comparison, and if you do, you'll find that the forecast trends continue to overlap the range of trend values despite the actual trend value swinging wildly because the range will naturally grow wider as the time period becomes shorter.
The bottom line that you have to ask yourself when generating these charts is "How is it possible that I can reach a different conclusion by looking at my chart to what I would infer from looking at Tom's or Tamino's chart (second figure in the OP)?" If the answer is not immediately obvious to you then you need to keep working on what the charts mean.
Dana goes to great length to attempt to explain that the left draft chart was a mistake due to baselining issues. My chart of the raw temperature data and Tom’s min/max model looks very similar to the draft IPCC chart. I doubt the people developing the draft chart made a major baseline mistake as claimed by Dana.
You shouldn't need to "doubt", it's obvious that they made a mistake. It makes no sense to anchor your projections on the temperature record for a particular year. The fact that you think Tom's chart "looks very similar to the draft IPCC chart" means you haven't understood the fact that by comparing trends alone Tom has completely sidestepped the issue.
If you really think you're onto something, then to prove it you should be able to do so using either Tom's chart or Tamino's. If you cannot, and you cannot say why Tom's chart or Tamino's chart do not support your claims, then you need to think a little bit more.
SAM... Actually, I find your chart interesting in terms of illustrating why there is a problem centering on 1990.
Look at your chart for a moment. Do you notice how 1990 is at the peak of the 5 year trend? Try centering the start point forward or back a few years and see if you get a different picture.
Do you see how you can get a very different interpretation by just adjusting a few years? That indicates to me that that method doesn't provide a robust conclusion. Centering on 1990 certainly provides a conclusion that skeptics prefer, but it's not at all robust.
But again, as JasonB just restated, you're treating this as an initial condition problem when it's a boundary condition problem. You have to look at the full band of model runs, including both hindcast and projections, and compare that (properly centered) to GMST data.
Another way of illustrating the problem with SASM's graph:
Keep the minimum and maximum trend lines the same as they are now but instead of plotting HadCRUT, plot instead the individual model realisations (Tom's spaghetti graph @ 79).
Now the model realisations will be going outside of the "minimum" and "maximum" trend lines, and many of them will be "pushing the limits" — if fact, no doubt some of them go outside those "limits". How is it possible that the actual model realisations that are used to create those "limits" could go beyond them? Because those "limits" are not the limits of the monthly (or five-yearly moving average) temperature realisations, they are the range of the trends of those realisations. And they certainly do not start at that particular point in 1990 — each realisation will have its own particular temperature (and five-year moving average) at that point in time.
Here is a graph based on my suggestions @122:
As you can see, HadCRUT4 does not drop below model minimum trends, alghough the ensemble 2.5th percentile certainly does. Nor does HadCRUT4 drop below the 2.5th percentile line recently (although it dropped to it in 1976).
Skeptics may complain that the trends are obviously dropped down with respect to the data. That is because the HadCRUT4 trendline is the actual trend line. Trendlines run through the center of the data, they do not start at the initial point.
I will be interested to hear SAM's comments as to why this graph is wrong or misleading, and why we must start the trends on a weighted 5 year average so as to ensure that HadCRUT4 drops below the lower trend line.
Following Tom's lead, here is a graph based on my suggestions @ 125:
I have simply taken Tom's graph @ 79 and plotted SASM's minimum and maximum trend lines starting at the same location and using the same slopes that SASM used.
As expected, there are quite a few model realisations that go much further beyond the supposed minimum and maximum than the actual temperature record does.
Given that those minimum and maximum trends were derived from the model realisations, and that applying this technique would lead to the nonsense conclusion that the models do not do a good job of predicting the models, clearly the approach is flawed.
Note also that shortly after the starting date, practically all of the models dramatically drop below the supposed minimum, thanks to Pinatubo! Indeed, at the start date, all of the models lie outside this supposed envelope. Again, this is because trend lines are being compared with actual temperatures.
On a different note:
In each of these cases, model temperatures are being compared to HadCRUT (and sometimes GISS) temperatures.
However, even this is not strictly an apples-to-apples comparison, as has been alluded to before when "masking" was mentioned. AFAIK the model temperatures being plotted are the actual global temperature anomalies for each model run in question, which are easy to calculate for a model. However, HadCRUT et al are attempts to reconstruct the true global temperature from various sources of information. There are differences between each of the global temperature reconstructions for the exact same actual temperature realisation, for known reasons. HadCRUT4, for example, is known to miss out on the dramatic warming of the Arctic because it makes the assumption (effectively) that temperature changes in unobserved areas are the same as the global average temperature change, whereas e.g. GISTEMP makes the assumption that temperature changes in those areas are the same as those in the nearest observed areas.
To really compare the two, the HadCRUT4 (and GISTEMP, and NOAA) algorithms should be applied to the model realisations as if they were the real world.
However, in the current circumstances, this is really nitpicking; even doing an apples-to-oranges comparison the real-world temperature reconstructions do not stand out from the model realisations. If they did then this would be one thing to check before jumping to any conclusions.
franklefkin wrote "Another thought. Perhaps the route you are suggesting is correct. If that is the case, why would the IPCC use the wrong ranges in AR4?"
The IPCC didn't use the wrong range for the subject of the discussion in the report (and at no point have I suggested otherwise). It just isn't a direct answer to the question that is being discussed here. Sadly you appear to be impervious to attempts to explain this to you, and are just repeating yourself, so I will leave the discussion there.
I though the science was settled on this issue?
Fyfe et al. (2013):
von Storch et al. (2013):
[JH] You are skating on the the thin ice of violating the following section of the SkS Comment Policy:
adeptus,
I haven't read Fyfe et al but looking at their Figure 1 you presented it strikes me that (a) the error margins on the HadCRUT4 trends are very narrow and (b) both 1993-2012 and 1998-2012 HadCRUT4 trends seem to have the same width.
Contrast this with the SkS Trend Calculator (which uses the method of Foster and Rahmstorf 2011) that gives a 2σ trend of 0.177 ±0.108 °C/decade for the former and 0.080 ±0.161 °C/decade for the latter. (And note that the trends calculated by the Trend Calculator do not take into account the fact that the start date is cherry picked, which 1998 almost certainly is.)
If the red hatched area in Figure 1a went from 0.069 to 0.285 °C/decade then it would cover about half the model trends; likewise, a red hatched area of -0.081 to 0.241 °C/decade in Figure 1b would cover about 2/3 of the model trends.
I think the reason for the differences in trend uncertainty is because Fyfe et al aren't trying to determine the true underlying long-term trend (which the SkS trend calculator is trying to determine) but rather they are assessing whether the models have accurately captured the short term variability with a view to seeing what is to "blame" (e.g. ENSO, aerosols, etc.).
As mentioned by Albatross here, Box TS.3, Figure 1a from AR5 looks to be the same as Figure 1b above:
Note that from 1984-1998 those same models underestimated the warming trend (1b). Yet from 1951-2012, they did a really good job indeed.
Therefore we can conclude that over short periods of time the models don't necessarily predict the actual, observed trend very well, but over long periods of time they do exceedingly well — and since what we're worried about is the long term effect, and not what the temperature is going to be next year, this is important. Also note that if you calculate the uncertainty in that observed trend to see what the range of possible values are for the underlying, long-term trend, there is a great deal of overlap even in shorter periods.
I wrote:
Contrast this with the SkS Trend Calculator (which uses the method of Foster and Rahmstorf 2011) that gives a 2σ trend of 0.177 ±0.108 °C/decade for the former and 0.080 ±0.161 °C/decade for the latter.
Sorry, accidentally used GISS. The HadCRUT4 figures are 0.155 ±0.105 °C/decade and 0.052 ±0.155 °C/decade, respectively.
BTW, to illustrate the perils of using short time periods, the HadCRUT4 trend for 2010-2012 is -1.242 ±1.964 °C/decade. Plotting the central trend on Fyfe et al's Figure 1 would put it far off the left of the chart. Would this prove that there was a problem with the models? Or that perhaps the time period is just too short to reach definitive conclusions?
Tom Curtis @126: I like your chart, and I usually like what you have to say or present. I understand the different between trend lines and comparing it to actual temperature data. At the origin (1990, +0.22 degC) of my chart @117 all lines are touching. As time advances forward, they are still very close and it is easy for the highly variable temperature data to go outside these lines (see the wide temperature swing in my chart @117 between 1998 and 2002). I think we all understand that this type of comparison isn’t meaningful in the initial stages of the forecast. But, as time advances forward the min/max trend lines become wider, and once they are as wide as the noisy temperature data, then the location of the origin really shouldn’t matter. For example, in your chart @126, you can see that the min/max trend lines are outside the 2.5%/97.5% model bands by 2013 or 2014.
Nevertheless, in both my chart and yours, it is clear that global temperatures are at the very low end of the model projections. You show the +/-2.5% bands and the current HADCRUT4 data is touching the lower 2.5% band. I read that as there was only a 2.5% chance that the global temperature would reach this level. This seems to indicate to me that the models are not very accurate. If you disagree, then how would any of you determine that the models are inaccurate? What is your method of testing and validation?
As a software modeler myself, testing is everything. In fact, in my world we have more test code than we have model code, and by a lot. Trying to gain confidence in a model is extremely difficult. Many of my models are very accurate, under specific and well defined circumstances, but outside of those conditions then my models are wildly wrong. Dana asserts in this post that “models have done much better than you think”, but for the life of me I cannot understand how he can make that claim. It doesn’t appear that Dana understands software modeling, and certainly not testing. And while I am not a GCM modeler, I have spent a bit of time reviewing the GISS Model E source code. I am not criticizing the developers of the code, but it is clear that engineers or physicists, not software engineers, have developed the code. Model E is not very large – about 100,000 lines of Fortran (a very old language) -- and some of the physics models I have examined (clouds, lapse rate, convection with respect to GCM cell size and iteration rates) are, IMO, simple and designed for limited computational resources. Yes, even with a zillion processors, what they are attempting to simulate is so complex and so large, that design and modeling simplifications have to be made. Otherwise the model will run too slow and not provide any output in our life time.
Those design and modeling simplifications are systematic errors, and essentially break the model. While I agree that true Gaussian errors will average out over time, systematic errors will not. Even very small systematic modeling errors – say 1%, which is impossible to achieve –will propagate over time and cascade into a large error. For example, let’s assume that GCMs are systematically accurate to within 1% on an annual basis. This means they *must* be able to model all aspects of the energy budget with accuracies greater than 1%. There is no way in hell they are doing that!!! Just look at the updated energy budget (http://www.nature.com/ngeo/journal/v5/n10/box/ngeo1580_BX1.html) and you can see that they have wide margins on every aspect of the budget. Climate scientists cannot measure the various components of the energy budget to within 1%, so there is no way they are modeling it to within 1%. A 1% systematic positively biased error will lead to an over estimation of +28% in 25 years (1.01 ^ 25 = 1.282), and in 100 years that same positive error will lead to an over estimation 170%.
In order for GCMs to be reliable for forecasting, there essentially cannot be any systematic errors within the model, and that is just not possible. To have no systematic error would require complete and total understanding of the climate (we don’t have that) and all physics models to include all first, second, third, and perhaps fourth order effects (and they don’t do that either). To make major economic and policy decisions based on the output of GCMs is pure and unadulterated foolishness. I form this opinion based on 30+ years of advance software modeling of physics based systems, and we are no where near 1% accuracy and what we’re working is way easier than modeling the climate. Just accept that the GCMs are wrong and not very accurate for forecasting, and that is okay; developing climate models should be useful in helping climate scientists understand the climate better. GCMs are just a tool, and like all tools they need to be used properly, otherwise someone is going to get hurt.
StealthAircraftSoftwareModeler, your claimed credentials seem more fictional the more you write. Would you really claim that "In order for aircraft models to be reliable for forecasting, there essentially cannot be any systematic errors within the model, and that is just not possible"?
Tom Dayton @134: I’m just curious, what is your background?
First, aircraft model are not extrapolating models at all in the way that GCM operate. Second, the progression from aircraft design to deployment is very complex, and extensive usage of models is employed to get “rough idea” of performance and features. Computer models are used in coarse design, then things progress to scale model testing in wind tunnels, but even because of the non linearity of aerodynamics and fluid properties, not even scale models are final. In the end, any thousands of hours of actual flight test of full size aircraft are used to *measure* control parameters. Rarely are model derived parameters used because of the very systematic errors of which I speak. Rest assured that the errors between the various stages of aircraft design and development easily exceed 1%. This is, in fact, the primary reason that aircraft development is so freaking expensive: test, and adjust, test and adjust, and on and on. Testing and adjusting never ever stops -- at least not until the aircraft is retired.
SAM @133, in fact HadCRUT4 only drops to the 8.38 percentile (%ile) in 2012, and to 7.87 %ile in 2011. In fact, over the entire period for which I have data for both CMIP 3 models and observations (1960-2012), it only once drops below the 2.5 %ile (to the 2.43 %ile) in 1976. It also drops to the 3.27 %ile in 1985 and to the 3.43 %ile in 1974.
That does not look like falsification to me. In fact, given that we have 53 years of record, we would expect the record to fall below the 2 %ile at least once in the period, but it does not. Partly that is because the two records are centered on their mean between 1961 and 1990, forcing HadCRUT4 to average close to the 50th percentile over that interval, but if the models were significantly in error, we would have expected a large number of instances where the observations were below the 2.5 %ile by now.
This is not to suggest that the models are not overpredicting the warming. They are, and the fact that they are is shown in the trend in percentile ranks seen above. However, that trend will not drop the observations consistenly below the 2.5% until 2035. Further, that trend is exagerated by the use of HadCRUT4 (which does not include regions of rapid warming which are included in the models). It is further exagerated by the final points observations being during a period of strong La Ninas.
Frankly, I am surprised that you and Klapper persist in trying to prove your point based on interpretations of the faulty 2nd order fig 1.4, and misinterpretation of significance intervals (which by definition, we expect to be crossed 5% of the time if the models are accurate). It would be far better to argue directly from the results of Foster and Rahmstorf, who show observed trends around 17 C/decade after adjustment for ENSO, solar variation and volcanism. That represents a 15% undershoot on the models; and a reasonable estimate of the discrepancy between models and observations.
SAM said... "Nevertheless, in both my chart and yours, it is clear that global temperatures are at the very low end of the model projections."
Once again, you don't seem to be grasping the boundary conditions aspect of this problem. Scientists do not expect the GMST to follow the model mean over shorter periods. The expect the GMST to remain roughly within the model bounds. Over longer timeframes (>30 years) we would expect to see a similar trend between GMST and model outputs.
SAM again... "I read that as there was only a 2.5% chance that the global temperature would reach this level."
Again, you're reading these as an initial conditions problem and not a boundary conditions problem.
If you look at any of the individual model runs, those are more likely what we would expect to see GMST do. And yes, they all wander from the 97.5%ile to the 2.5%ile. So, your statement would be inaccurate.
SAM... You seem to have a particular interest in this issue, and it's somewhat related to your own professional expertise. And yet you seem to be failing to grasp some basic elements of GCM work.
My suggestion would be that you try to contact a researcher who is actually doing work on GCM's. I've always found researchers to be very communicative with people interested in their work. I'm sure they could help you understand their work.
This is what I believe Admiral Tilly of the US Navy did when he was skeptical of AGW. Once he had the issue of climate modeling explained to him he began to take the threats of climate change seriously.
Stealth, your comment "First, aircraft model are not extrapolating models at all in the way that GCM operate" is irrelevant in the face of clear evidence that GCMs are successful.
Your statement "Second, the progression from aircraft design to deployment is very complex, and extensive usage of models is employed to get 'rough idea' of performance and features" is exactly true of every model, computerized or not, in every field of endeavor, throughout human history. The critical piece is the definition of "rough" in each particular use of a particular model: Is the model sufficiently accurate to serve the particular use to which you are putting it? As noted in the original post, climate models have indeed proven accurate enough to provide the information we need to choose actions to reduce greenhouse gas emissions, because the costs of not reducing are and will be far higher than the costs of reducing.
You continue to claim that climate models cannot project well enough for that use, despite the clear and robust evidence that they have, do, and will. You might as well be a newspaper editor in the early 1900s refusing to publish any reports of the Wright brothers' successful flights despite photos and your reporters' first-hand accounts, because you "know" that flight is impossible.
As for my background: PhD in cognitive science with focus on decision theory (normative and behavioral), scientific research methodology, human-computer interaction, and the combination of all those in how to use computers as decision making tools. Employment for 24 years after that, in designing software and managing software development projects. For the first 7 years of that, for the major telecommunications systems in the world. The second 7 years for critical, large scale computer server and network management. For the past 10 years, for spacecraft (both flight software that runs on the spacecraft, and ground software for mission operations).
(-snip-). That is hogwash. You cannot have accurate long term forecasts and inaccurate short term forecasts.
Rob @137 and @138: I may not be understanding the “boundary conditions” -- please explain what it is. And for the record I am referencing Tom Curtis’ chart @126. It does not, I believe, have any of the “initial conditions” you mention. The boundary in Tom’s chart @126 seems to be well defined edges of accuracy and unlikely to be crossed. But if it can be crossed and the model still be correct, then what has to happen to determine that the model is inaccurate?
[DB] Sloganeering snipped.
My bad. I asked for some background info and didn't see Tom's post that came in while I was typing. I'm really trying to have a good discussion and not be a jerk denier, because I'm not one. (-snip-).
[DB] Sloganeering snipped. You have been pointed to resources which countermand your position. Unless you have new evidence, it is time to drop it.
Yes Stealth, your attempt to "not be a jerk" is failing. You are vastly overestimating the breadth of your knowledge by making such ridiculous assertions as "That is hogwash. You cannot have accurate long term forecasts and inaccurate short term forecasts," when that has been explained to you over and over and over for weeks (months?). Once more, for an explanation see "The Difference Between Weather and Climate." For even more, see "Chaos Theory and Global Warming: Can Climate Be Predicted?"
"You are vastly overestimating the breadth of your knowledge by making such ridiculous assertions....when that has been explained to you over and over and over for weeks...."
[PW[ Indeed, and from now on, a newly-coined parameter will be taken into account, when posters do this. It's called 'anterograde amnesia,' and continuing utilization of the technique will be considered obfuscatory, and will be appropriately moderated. Tom Curtis has patiently explained such things to you, Stealth, and you've consistently acted as if the news was...well, new. No more.
Stealth, for even more about initial values versus boundary conditions, see Steve Easterbrook's post. While you're at it, go to RealClimate's Index, scroll down to the section "Climate Modelling," and read all of the posts listed there. For example, in the post "Is Climate Modelling Science?", there appears:
"I use the term validating not in the sense of ‘proving true’ (an impossibility), but in the sense of ‘being good enough to be useful’). In essence, the validation must be done for the whole system if we are to have any confidence in the predictions about the whole system in the future. This validation is what most climate modellers spend almost all their time doing."
For the umpteenth time: You need to read the Skeptical Science post "How Reliable Are Climate Models?", including both the Basic and the Advanced tabs.
For a broader and deeper discussion of how climate models are verified and validated (V&Ved), read software professor and former NASA software quality assurance guy Steve Easterbrook's explanation.
A good, short, essay on the role of computer models in science is in the journal Communications of the ACM, the September 2010 issue, page 5: Science Has Only Two Legs.
Stealth, you wrote:
This and similar comments, along with your login name, appear to be attempts to pull rank by virtue of your software 'expertise'.
In fact, programming software is fairly easy for anyone with a basic sense of syntax and logic. The difficulty with software modelling is not really in the writing of the code, but in understanding the domain you are trying to model. You clearly have very little knowledge of the climate domain, and you seem resistant to the patient attempts of others to educate you.
You also wrote:
This patently false comment reveals that you do not understand - even in the broadest terms - what the models are trying to achieve and how they relate to the real world, perhaps because you are drawing faulty analogies with the one domain you do understand (aviation modelling). There are countless situations where long-term projections are possible despite short-term unpredictability.
For instance:
Some systems are highly divergent, and small-short term effects propagate to create vastly different outcomes, like the proverbial butterfly flap. But others are highly convergent, and small short-term effects are swallowed up. This is particularly the case for climate modelling, when many of the short-term effects are merely moving heat around within the system, without substantially changing the cumulative and predictable heat imbalance due to GHGs.
Stealth does not appear to understand the difference between boundary and initial value problems.
Consider as an example Los Angeles freeway traffic. Predicting exact volume even a few hours from now (initial value problem) would require exact numbers of cars on the road, perhaps some estimates of how aggressively they are being driven, detailed road conditions, etc. From that you could make detailed and relatively exact projections of how traffic might behave a few hours later. But not for a week down the line - there's too much that can occur in the meantime.
If, however, you wish to make long term projections of what traffic might be (boundary value problem) - given information on population, predictions on neighborhood growth, planned on/off ramp construction, and perhaps the football schedule (for near-stadium effects), you can make an average traffic prediction years down the road. You won't be able to predict the exact number of cars passing a point on the road on a particular Tuesday five years ahead - but you can make excellent predictions of the averages. And in fact city planners do this all the time.
In terms of evaluating climate models, whose mean trends are a boundary value solution - the climate has many short term variations, and it is only to be expected that short term variations will indeed occur around energy bounded long term trends. Models are quite frankly doing very well right now:
[Source]
In order for the models to be invalidated by observations, the long term trend would have to go beyond the boundaries - far enough that such a new trend +/- the range of variation departed from the model predictions +/- variations. That hasn't happened, not by a long shot - and (IMO) it won't, as we have a pretty good handle on the physics.
In the meantime, demanding impossible perfection from boundary condition models, in the presence of short term initial value variations, is just a logical fallacy.
"You cannot have accurate long term forecasts and inaccurate short term forecasts."
Um, I can forecast the average temperature for the month of May next year I suspect with greater accuracy than I can predict the average daily temperature for Sunday week times That is rather like the difference between weather and climate.
As to background - I program models for, among other things, thermal evolution of sedimentary basins and in particular the evolution of hydrocarbon geochemistry over time. This is to answer the questions like "does this basin produce hydrocarbons, and if so, when, how much and in what phases". More than most however, the problem is dominated by uncertainty and poor constraints.
Stealth - "I’m just curious, what is your background?"
An Argument from Authority is a logical fallacy - it's the strength of the evidence and argument that matters, not the credentials of the person presenting a position. And regardless of your background, you have not supported your posts.
I just flipped 7 heads and 3 tails. The model that predicts very nearly 50%/50% distribution over 1000 coin flips, then, cannot be right.
Leto @ 145,
A professional poker player sits down with a novice. The hands and flow of money are totally unpredictable in the short term, but we know who is going to win by the end of the evening
In fact, the entire casino industry is based on the fact that over a large number of games with a large number of people, a small bias in favour of the house will give them a profit even if they can't predict whether they will win or lose any particular game.