






























 Arguments
Arguments





















Understanding adjustments to temperature data
Posted on 26 February 2015 by Guest Author
This is a guest post by Zeke Hausfather
There has been much discussion of temperature adjustment of late in both climate blogs and in the media, but not much background on what specific adjustments are being made, why they are being made, and what effects they have. Adjustments have a big effect on temperature trends in the U.S., and a modest effect on global land trends. The large contribution of adjustments to century-scale U.S. temperature trends lends itself to an unfortunate narrative that “government bureaucrats are cooking the books”.
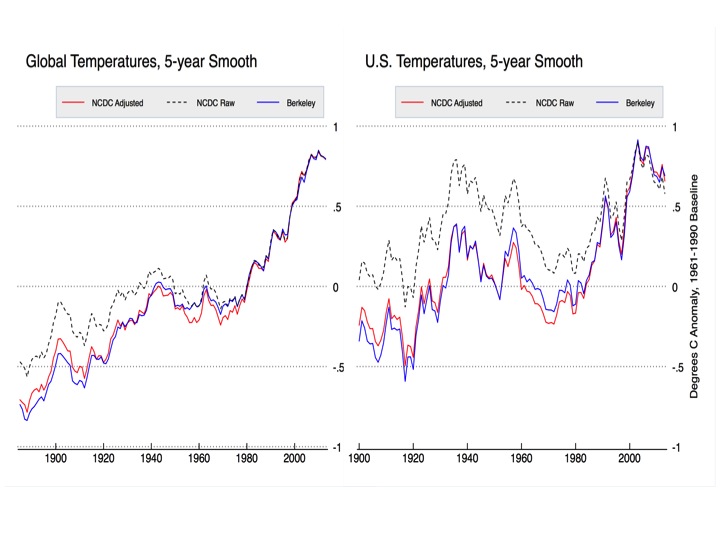
Figure 1. Global (left) and CONUS (right) homogenized and raw data from NCDC and Berkeley Earth. Series are aligned relative to 1990-2013 means. NCDC data is from GHCN v3.2 and USHCN v2.5 respectively.
Having worked with many of the scientists in question, I can say with certainty that there is no grand conspiracy to artificially warm the earth; rather, scientists are doing their best to interpret large datasets with numerous biases such as station moves, instrument changes, time of observation changes, urban heat island biases, and other so-called inhomogenities that have occurred over the last 150 years. Their methods may not be perfect, and are certainly not immune from critical analysis, but that critical analysis should start out from a position of assuming good faith and with an understanding of what exactly has been done.
This will be the first post in a three-part series examining adjustments in temperature data, with a specific focus on the U.S. land temperatures. This post will provide an overview of the adjustments done and their relative effect on temperatures. The second post will examine Time of Observation adjustments in more detail, using hourly data from the pristine U.S. Climate Reference Network (USCRN) to empirically demonstrate the potential bias introduced by different observation times. The final post will examine automated pairwise homogenization approaches in more detail, looking at how breakpoints are detected and how algorithms can tested to ensure that they are equally effective at removing both cooling and warming biases.
Why Adjust Temperatures?
There are a number of folks who question the need for adjustments at all. Why not just use raw temperatures, they ask, since those are pure and unadulterated? The problem is that (with the exception of the newly created Climate Reference Network), there is really no such thing as a pure and unadulterated temperature record. Temperature stations in the U.S. are mainly operated by volunteer observers (the Cooperative Observer Network, or co-op stations for short). Many of these stations were set up in the late 1800s and early 1900s as part of a national network of weather stations, focused on measuring day-to-day changes in the weather rather than decadal-scale changes in the climate.
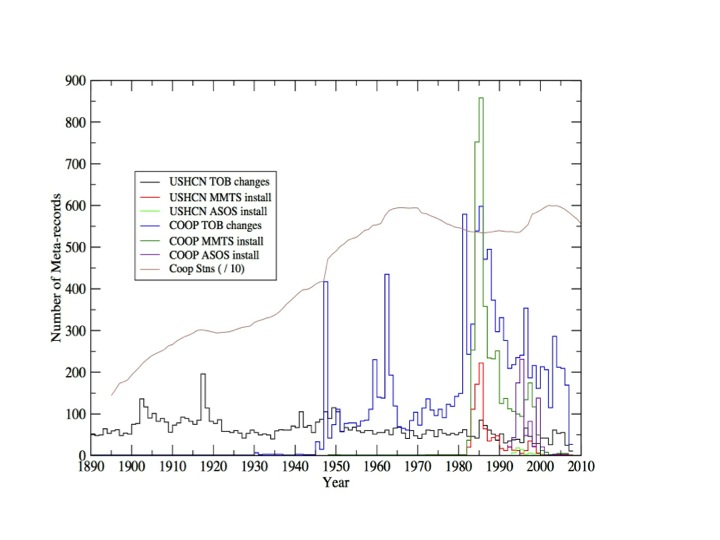
Figure 2. Documented time of observation changes and instrument changes by year in the co-op and USHCN station networks. Figure courtesy of Claude Williams (NCDC).
Nearly every single station in the network in the network has been moved at least once over the last century, with many having 3 or more distinct moves. Most of the stations have changed from using liquid in glass thermometers (LiG) inStevenson screens to electronic Minimum Maximum Temperature Systems(MMTS) or Automated Surface Observing Systems (ASOS). Observation times have shifted from afternoon to morning at most stations since 1960, as part of an effort by the National Weather Service to improve precipitation measurements.
All of these changes introduce (non-random) systemic biases into the network. For example, MMTS sensors tend to read maximum daily temperatures about 0.5 C colder than LiG thermometers at the same location. There is a very obvious cooling bias in the record associated with the conversion of most co-op stations from LiG to MMTS in the 1980s, and even folks deeply skeptical of the temperature network like Anthony Watts and his coauthors add an explicit correction for this in their paper.

Figure 3. Time of Observation over time in the USHCN network. Figure from Menne et al 2009.
Time of observation changes from afternoon to morning also can add a cooling bias of up to 0.5 C, affecting maximum and minimum temperatures similarly. The reasons why this occurs, how it is tested, and how we know that documented time of observations are correct (or not) will be discussed in detail in the subsequent post. There are also significant positive minimum temperature biases from urban heat islands that add a trend bias up to 0.2 C nationwide to raw readings.
Because the biases are large and systemic, ignoring them is not a viable option. If some corrections to the data are necessary, there is a need for systems to make these corrections in a way that does not introduce more bias than they remove.
What are the Adjustments?
Two independent groups, the National Climate Data Center (NCDC) and Berkeley Earth (hereafter Berkeley) start with raw data and use differing methods to create a best estimate of global (and U.S.) temperatures. Other groups like NASA Goddard Institute for Space Studies (GISS) and the Climate Research Unit at the University of East Anglia (CRU) take data from NCDC and other sources and perform additional adjustments, like GISS’s nightlight-based urban heat island corrections.

Figure 4. Diagram of processing steps for creating USHCN adjusted temperatures. Note that TAvg temperatures are calculated based on separately adjusted TMin and TMax temperatures.
This post will focus primarily on NCDC’s adjustments, as they are the official government agency tasked with determining U.S. (and global) temperatures. The figure below shows the four major adjustments (including quality control) performed on USHCN data, and their respective effect on the resulting mean temperatures.
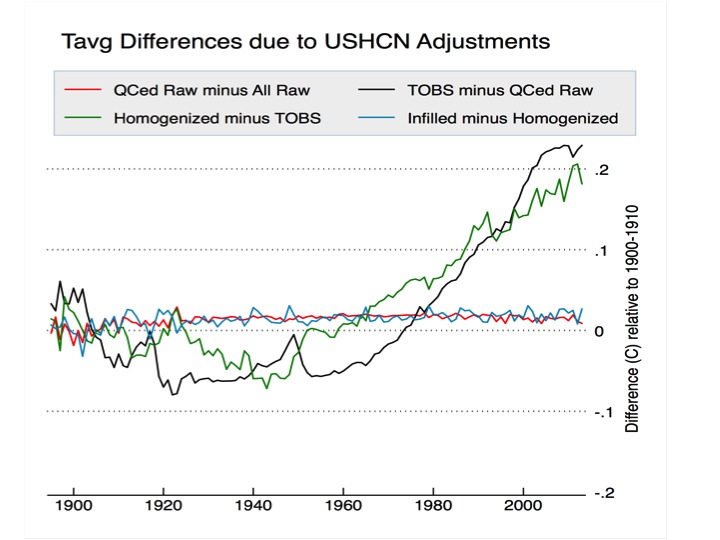
Figure 5. Impact of adjustments on U.S. temperatures relative to the 1900-1910 period, following the approach used in creating the old USHCN v1 adjustment plot.
NCDC starts by collecting the raw data from the co-op network stations. These records are submitted electronically for most stations, though some continue to send paper forms that must be manually keyed into the system. A subset of the 7,000 or so co-op stations are part of the U.S. Historical Climatological Network (USHCN), and are used to create the official estimate of U.S. temperatures.
Quality Control
Once the data has been collected, it is subjected to an automated quality control (QC) procedure that looks for anomalies like repeated entries of the same temperature value, minimum temperature values that exceed the reported maximum temperature of that day (or vice-versa), values that far exceed (by five sigma or more) expected values for the station, and similar checks. A full list of QC checks is available here.
Daily minimum or maximum temperatures that fail quality control are flagged, and a raw daily file is maintained that includes original values with their associated QC flags. Monthly minimum, maximum, and mean temperatures are calculated using daily temperature data that passes QC checks. A monthly mean is calculated only when nine or fewer daily values are missing or flagged. A raw USHCN monthly data file is available that includes both monthly values and associated QC flags.
The impact of QC adjustments is relatively minor. Apart from a slight cooling of temperatures prior to 1910, the trend is unchanged by QC adjustments for the remainder of the record (e.g. the red line in Figure 5).
Time of Observation (TOBs) Adjustments
Temperature data is adjusted based on its reported time of observation. Each observer is supposed to report the time at which observations were taken. While some variance of this is expected, as observers won’t reset the instrument at the same time every day, these departures should be mostly random and won’t necessarily introduce systemic bias. The major sources of bias are introduced by system-wide decisions to change observing times, as shown in Figure 3. The gradual network-wide switch from afternoon to morning observation times after 1950 has introduced a CONUS-wide cooling bias of about 0.2 to 0.25 C. The TOBs adjustments are outlined and tested in Karl et al 1986 and Vose et al 2003, and will be explored in more detail in the subsequent post. The impact of TOBs adjustments is shown in Figure 6, below.
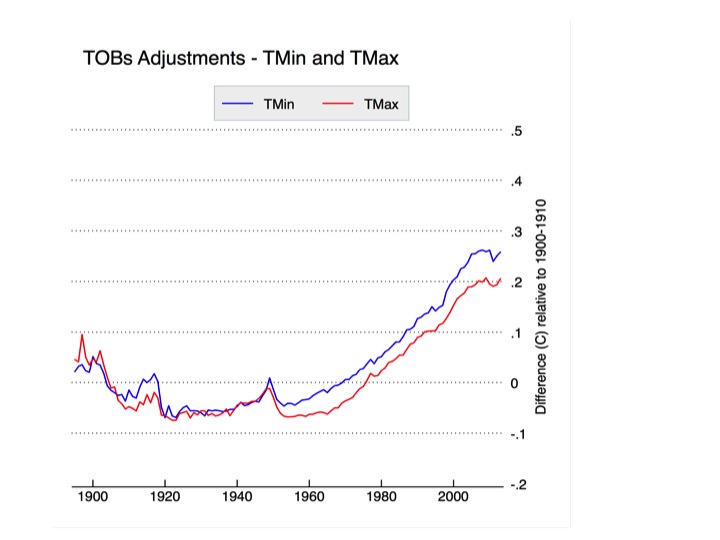
Figure 6. Time of observation adjustments to USHCN relative to the 1900-1910 period.
TOBs adjustments affect minimum and maximum temperatures similarly, and are responsible for slightly more than half the magnitude of total adjustments to USHCN data.
Pairwise Homogenization Algorithm (PHA) Adjustments
The Pairwise Homogenization Algorithm was designed as an automated method of detecting and correcting localized temperature biases due to station moves, instrument changes, microsite changes, and meso-scale changes like urban heat islands.
The algorithm (whose code can be downloaded here) is conceptually simple: it assumes that climate change forced by external factors tends to happen regionally rather than locally. If one station is warming rapidly over a period of a decade a few kilometers from a number of stations that are cooling over the same period, the warming station is likely responding to localized effects (instrument changes, station moves, microsite changes, etc.) rather than a real climate signal.
To detect localized biases, the PHA iteratively goes through all the stations in the network and compares each of them to their surrounding neighbors. It calculates difference series between each station and their neighbors (separately for min and max) and looks for breakpoints that show up in the record of one station but none of the surrounding stations. These breakpoints can take the form of both abrupt step-changes and gradual trend-inhomogenities that move a station’s record further away from its neighbors. The figures below show histograms of all the detected breakpoints (and their magnitudes) for both minimum and maximum temperatures.
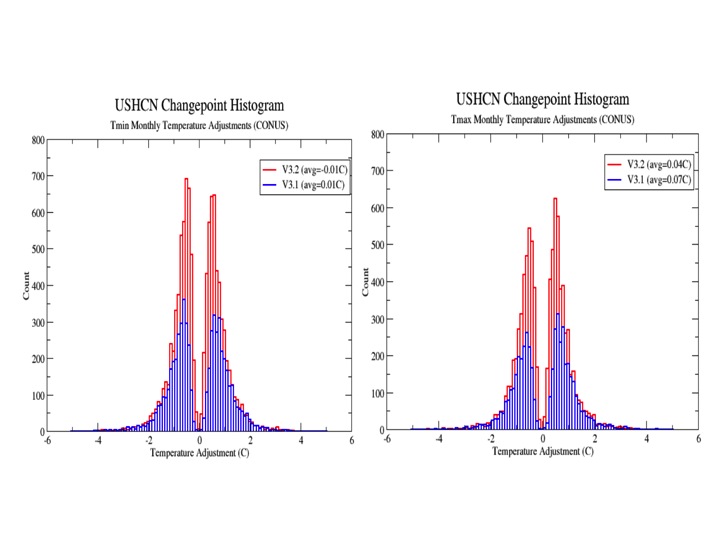
Figure 7. Histogram of all PHA changepoint adjustments for versions 3.1 and 3.2 of the PHA for minimum (left) and maximum (right) temperatures.
While fairly symmetric in aggregate, there are distinct temporal patterns in the PHA adjustments. The single largest of these are positive adjustments in maximum temperatures to account for transitions from LiG instruments to MMTS and ASOS instruments in the 1980s, 1990s, and 2000s. Other notable PHA-detected adjustments are minimum (and more modest maximum) temperature shifts associated with a widespread move of stations from inner city rooftops to newly-constructed airports or wastewater treatment plants after 1940, as well as gradual corrections of urbanizing sites like Reno, Nevada. The net effect of PHA adjustments is shown in Figure 8, below.

Figure 8. Pairwise Homogenization Algorithm adjustments to USHCN relative to the 1900-1910 period.
The PHA has a large impact on max temperatures post-1980, corresponding to the period of transition to MMTS and ASOS instruments. Max adjustments are fairly modest pre-1980s, and are presumably responding mostly to the effects of station moves. Minimum temperature adjustments are more mixed, with no real century-scale trend impact. These minimum temperature adjustments do seem to remove much of the urban-correlated warming bias in minimum temperatures, even if only rural stations are used in the homogenization process to avoid any incidental aliasing in of urban warming, as discussed in Hausfather et al. 2013.
The PHA can also effectively detect and deal with breakpoints associated with Time of Observation changes. When NCDC’s PHA is run without doing the explicit TOBs adjustment described previously, the results are largely the same (see the discussion of this in Williams et al 2012). Berkeley uses a somewhat analogous relative difference approach to homogenization that also picks up and removes TOBs biases without the need for an explicit adjustment.
With any automated homogenization approach, it is critically important that the algorithm be tested with synthetic data with various types of biases introduced (step changes, trend inhomogenities, sawtooth patterns, etc.), to ensure that the algorithm will identically deal with biases in both directions and not create any new systemic biases when correcting inhomogenities in the record. This was done initially in Williams et al 2012 and Venema et al 2012. There are ongoing efforts to create a standardized set of tests that various groups around the world can submit homogenization algorithms to be evaluated by, as discussed in our recently submitted paper. This process, and other detailed discussion of automated homogenization, will be discussed in more detail in part three of this series of posts.
Infilling
Finally we come to infilling, which has garnered quite a bit of attention of late due to some rather outlandish claims of its impact. Infilling occurs in the USHCN network in two different cases: when the raw data is not available for a station, and when the PHA flags the raw data as too uncertain to homogenize (e.g. in between two station moves when there is not a long enough record to determine with certainty the impact that the initial move had). Infilled data is marked with an “E” flag in the adjusted data file (FLs.52i) provided by NCDC, and its relatively straightforward to test the effects it has by calculating U.S. temperatures with and without the infilled data. The results are shown in Figure 9, below:
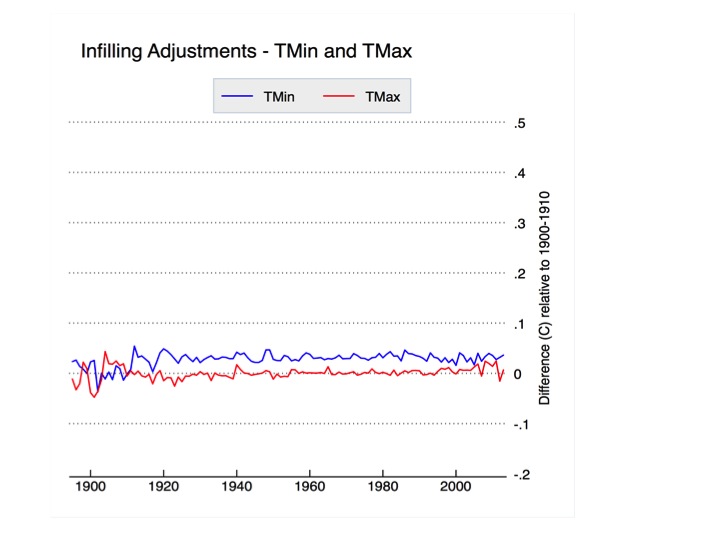
Figure 9. Infilling-related adjustments to USHCN relative to the 1900-1910 period.
Apart from a slight adjustment prior to 1915, infilling has no effect on CONUS-wide trends. These results are identical to those found in Menne et al 2009. This is expected, because the way NCDC does infilling is to add the long-term climatology of the station that is missing (or not used) to the average spatially weighted anomaly of nearby stations. This is effectively identical to any other form of spatial weighting.
To elaborate, temperature stations measure temperatures at specific locations. If we are trying to estimate the average temperature over a wide area like the U.S. or the Globe, it is advisable to use gridding or some more complicated form of spatial interpolation to assure that our results are representative of the underlying temperature field. For example, about a third of the available global temperature stations are in U.S. If we calculated global temperatures without spatial weighting, we’d be treating the U.S. as 33% of the world’s land area rather than ~5%, and end up with a rather biased estimate of global temperatures. The easiest way to do spatial weighting is using gridding, e.g. to assign all stations to grid cells that have the same size (as NASA GISS used to do) or same lat/lon size (e.g. 5×5 lat/lon, as HadCRUT does). Other methods include kriging (used by Berkeley Earth) or a distance-weighted average of nearby station anomalies (used by GISS and NCDC these days).
As shown above, infilling has no real impact on temperature trends vs. not infilling. The only way you get in trouble is if the composition of the network is changing over time and if you do not remove the underlying climatology/seasonal cycle through the use of anomalies or similar methods. In that case, infilling will give you a correct answer, but not infilling will result in a biased estimate since the underlying climatology of the stations is changing. Thishas been discussed at length elsewhere, so I won’t dwell on it here.
I’m actually not a big fan of NCDC’s choice to do infilling, not because it makes a difference in the results, but rather because it confuses things more than it helps (witness all the sturm und drang of late over “zombie stations”). Their choice to infill was primarily driven by a desire to let people calculate a consistent record of absolute temperatures by ensuring that the station composition remained constant over time. A better (and more accurate) approach would be to create a separate absolute temperature product by adding a long-term average climatology field to an anomaly field, similar to the approach that Berkeley Earth takes.
Changing the Past?
Diligent observers of NCDC’s temperature record have noted that many of the values change by small amounts on a daily basis. This includes not only recent temperatures but those in the distant past as well, and has created some confusion about why, exactly, the recorded temperatures in 1917 should change day-to-day. The explanation is relatively straightforward. NCDC assumes that the current set of instruments recording temperature is accurate, so any time of observation changes or PHA-adjustments are done relative to current temperatures. Because breakpoints are detected through pair-wise comparisons, new data coming in may slightly change the magnitude of recent adjustments by providing a more comprehensive difference series between neighboring stations.
When breakpoints are removed, the entire record prior to the breakpoint is adjusted up or down depending on the size and direction of the breakpoint. This means that slight modifications of recent breakpoints will impact all past temperatures at the station in question though a constant offset. The alternative to this would be to assume that the original data is accurate, and adjusted any new data relative to the old data (e.g. adjust everything in front of breakpoints rather than behind them). From the perspective of calculating trends over time, these two approaches are identical, and its not clear that there is necessarily a preferred option.
Hopefully this (and the following two articles) should help folks gain a better understanding of the issues in the surface temperature network and the steps scientists have taken to try to address them. These approaches are likely far from perfect, and it is certainly possible that the underlying algorithms could be improved to provide more accurate results. Hopefully the ongoing International Surface Temperature Initiative, which seeks to have different groups around the world send their adjustment approaches in for evaluation using common metrics, will help improve the general practice in the field going forward. There is also a week-long conference at NCAR next week on these issues which should yield some interesting discussions and initiatives.









{kind=link}
Tom Dayton. Great explanation! Thanks again. "Stefan_Z" has gone off the grid since I slapped him with some of this info that you and Tom C. provided.
My mission continues: "Saving the world from willfull ignorance, even if it's only one denier at a time."
Quick
And another point to remember for future reference. 70% of the world is oceans and the major temperature series are land and ocean combined data. Land surface air temperatures and ocean sea surface temperatures. Much of the recent peak was due to warmer SST's, particulaly in the north pacific.
And SST's are measured by satellites, not RTD's.
Glenn Tamblyn @52, until recently GISS used surface observation based data for SST except for the last few years in which they used satellite based data. They now use NOAA ERSST which in turn is based on ICOADS, a dataset of surface based observations. The HadCRUT4 index uses the HadSST3 dataset for SST, which is in turn also based on ICOADS. The NCDC (NOAA) uses the ERSST. BEST (Berkeley) uses HadSST3. UAH and RSS use satellite observations exclusively, but observer the atmosphere rather than the surface, and hence do not have observations of SST directly. Consequently I am unaware of any commonly used temperature series that currently uses satellite observations of SST.
Tom, my reading of the metadata for ersst is that they use satellite data from 1985, since v3 as well as icoads and Huang v4 change method but not input.
scaddenp @54, the ERSST v3 introduced the use of satellite data, but in v3b, they ceased using satellite data as it introduced an identified spurious cold trend due to difficulties in determining clear sky conditions. I do not have access to the full paper of Huang et al (2014) so I don't know if v4 reintroduced satellite data again. I note, however, that satellites are mentioned only twice in the abstract, once with reference to an institutional affiliation, and once with reference to a cross product comparison. That suggests that they have not.
As a side note, Liu et al (2014) is the estimate of uncertainty for ERSST v4 - further ammunition for Quick if he still needs it ;)
Quick,
As a demonstration of what Tom Curtis and Tom Dayton have been sayng, I wrote a quick Java program. It produces 5000 random values between 0 and 20, computes the average and then "warms" them by adding 0.002 to each value and recomputing the average. Not surprisingly, the new average is close to 0.002 above the old one (some errors creep in because of Java inaccuracies - these could be fixed with a more sophisticated approach.)
When the initial and adjusted values are accessed through surrogate values that have been rounded to the nearest 0.1, the difference between the averages is still very close to 0.002 - even though most of the rounded values are the same before and after the warming, just enough are increased that, on average, the 0.002 warming can be recovered.
Typical output:
Test of ability to measure difference of 0.002 with 5000 instruments rounded to nearest 0.1
Start with 5000 random values in range 0 to 20
Sample:
Baseline Warmed
17.555315017700195 17.557315017700194
6.136661529541016 6.138661529541015
12.851906776428223 12.853906776428223
18.39383888244629 18.395838882446288
3.099104166030884 3.1011041660308836
5.749928951263428 5.7519289512634275
18.21527862548828 18.21727862548828
2.304227352142334 2.3062273521423338
5.495196342468262 5.4971963424682615
7.890586853027344 7.8925868530273435
Average of initial values 10.034636362266541
... add 0.002 to each value
Average of new values 10.036636362266911
True difference 0.00200000000037015
Now round initial and final data sets to nearest 0.1...
Sample:
Baseline Warmed
17.6 17.6
6.1 6.1
12.9 12.9
18.4 18.4
3.1 3.1
5.7 5.8 *
18.2 18.2
2.3 2.3
5.5 5.5
7.9 7.9
Average of rounded values 10.034260000000016
Average of rounded new values 10.036380000000015
Measured difference derived solely from rounded values 0.0021199999999996777
Output is different every time, but the general principle holds.
Code below:
/////////////////////////////////////////////////
import java.util.Random;
public class Average {
static double[] values ;
static double[] newValues ;
private static final int NUMVALUES = 5000 ;
static Random random = new Random();
public static void main(String[] args){
System.out.println("Test of ability to measure difference of 0.002 with " + NUMVALUES + " instruments rounded to nearest 0.1\n") ;
System.out.println("Start with 5000 random values in range 0 to 20" );
values = new double[NUMVALUES] ;
newValues = new double[NUMVALUES] ;
for(int n=0; n<NUMVALUES; n++){
values[n] = random.nextFloat()*20;
newValues[n]=values[n]+ 0.002d ;
}
double average = Average(values) ;
double newAverage = Average(newValues) ;
double[] roundedValues = Rounded(values) ;
double[] roundedNewValues = Rounded(newValues) ;
double measuredAverage = Average(roundedValues) ;
double newMeasuredAverage = Average(roundedNewValues) ;
System.out.println(" Sample:\nBaseline\t\tWarmed" );
for(int n=0; n<10; n++) {
System.out.println(" " + values[n] + "\t " + newValues[n] );
}
System.out.println(" Average of initial values " + average);
System.out.println(" ... add 0.002 to each value ");
System.out.println(" Average of new values " + newAverage);
System.out.println(" True difference " + (newAverage-average)) ;
System.out.println();
System.out.println("Now round initial and final data sets to nearest 0.1..." );
System.out.println(" Sample:\nBaseline\tWarmed" );
for(int n=0; n<10; n++) {
System.out.print(" " + roundedValues[n] + "\t\t" + roundedNewValues[n] );
if(roundedValues[n]!=roundedNewValues[n])
System.out.print(" *");
System.out.println();
}
System.out.println(" Average of rounded values " + measuredAverage);
System.out.println(" Average of rounded new values " + newMeasuredAverage);
System.out.println(" Measured difference derived solely from rounded values " + (newMeasuredAverage-measuredAverage)) ;
}
private static double Average(double[] vals){
int len = vals.length ;
double sum = 0 ;
for(int n=0; n<len; n++){
sum+=vals[n];
}
return sum/len ;
}
private static double[] Rounded(double[] vals){
int len = vals.length ;
double[] rounded = new double[len] ;
for(int n=0; n<len; n++){
rounded[n] = (int)(vals[n]*10 + 0.5f);
rounded[n]/=10f ;
}
return rounded ;
}
}
/////////////////////////////////////////////////
Leto @56, the most stunning use of these principles I know of actually comes from amateur astronomy. In a new technique, amateur astronomers take thousands of images of the object they are interested in. They then use computer programs to "average" the images. The result is an image far sharper than any of the individual images used, and indeed sharper than they could achieve with the same exposure time using conventional techniques. For example, these three images were taken on a 16 inch newtonian telescope:
And this is one of the individual images from the "stack" used to create the Jupiter image above:
The truly amazing thing here is that not only does averaging bring out a far higher resolution image, but without the introduction of noise by the atmosphere, all the images in the stack would be identical, and no image improvement would be possible. So, in this case not only does averaging eliminate noise, and allow a far higher resolution than is possible by the original instruments, but the noise is in fact necessary for the process.
Although I am not in disagreement with what has been disucssed in the last few days, there is another characteristic of temperature sensors that has been missed. Although the previously-mentioned accuracy of +/-0.1C is fairly typical of meteorological sensors, that accuracy specification does not quite mean what some seem to be assuming it means.
For example, Vaisala is a manufacturer of very commonly-used meteorological sensors, and they make a combined humidity/temperature probe (HMP155) that is in widespread use. It specifies a +/-0.1C accuracy. That value, however, is not a random error for a single reading from the instrument - it is the random error for a large number of instruments over the temperature range in question. What that means is if that you buy 100 HMP155s, they will all tell you the same temperature to within +/-0.1.
For a single sensor/instrument, however, the error is not particularly random. A specific sensor will typically be a bit high or a bit low, and will remain at a pretty constant offset from the real temperature. So, when looking at a change in temperature, you can accurately detect a very small change, even though you're not quite sure of the exact temperature itself.
Mathematically, the error in the temperature change is related to the error in each reading as follows:
which makes
If error2 and error1 are the same, there is no error in the difference. Note that the above equation applies to one specific pair of readings, not the distribution of errors for a large number of readings.
The key factor, when considering the distribution of errors (i.e., what errors are expected from a large number of pairs of readings) is the covariance between errors. If the covariance is zero (the two errors are completely independent) then we have random errors, and the whole averaging process described above will apply. When the two errors vary in lock-step, the sensor can have very poor absolute accuracy and still detect small changes accurately from a single pair of readings. WIkipedia's Propagation of Uncertainty page does a reasonable job of discussing some general principles.
Given that any normal weather station and network of stations will keep a single instrument installed at a single station for a long time, it is the error relationship for that individual that is important. Even at a single station, over a short period of time, temperature changes can be measured accurately.
Bob @ 58,
Very good points. The common practice of reporting a single error range for an instrument doesn't help general understanding. It would be nice if it were standard practice to separate out components that are random from reading to reading (and hence average out) versus components that are systematic/consistent (and hence irrelevant to measuring changes). There is a spectrum between these types of errors (and other subtleties as explained in your post), but some convenient way of reporting both error dimensions would be nice.
My quick Java example is of course based on an unrealistic error distribution introduced artificially by rounding. In that example, an increase of 0.002 is manifested as a one fiftieth chance of a 0.1 upwards step occurring. In a real instrument, there would be a more complex error distribution.
As someone else said up above, this could be a topic for another SkS post. There does seem to be significant confusion on the issue in denierville.
Tom Curtis @ 57,
Nice pics. The example best known to me is picking up the tiny elecrical signal coming from the first phase of visual processing, and hence measuring the speed of transmission in the optic nerve non-invasively, merely by averaging out the time-locked EEG signal over the back of the head while a subject looks at a flashing checkerboard pattern. Everything evenually averages out to nothing apart from the activity that is locked to the flashing.
@ 57, I read The Mechanism of Mind by Edward Debono once and he was saying that the error of the mind was what made it work so efficiently and/or effectively plus or minus a few definitions of accuracy(lol)... so kind of the same thing!! (...it was a repetition versus error type scenario like what you are saying, perhaps!)
- perhaps not, but I'm willing to bet the book has bred ideas!
..more like a "repetition versus error-of-repetition"(my summation atleast) concept according to him... but I only read 3/4 of it I must admit before I lost the thread so,..!!
Where is part two and part three of this series?
[JH] Click on the Lessons from Predicitions button in the upper right hand corner of the article.
I don't see a Lessons from Predictions in the upper right–hand corner. Where are parts 2 & 3??
frankprice @63: I located Zeke's 2nd installment: Understanding Time of Observation Bias, but I'm not sure what/where the 3rd installment is. That post was supposed to be about "automated pairwise homogenization".