






























 Arguments
Arguments





















Understanding adjustments to temperature data
Posted on 26 February 2015 by Guest Author
This is a guest post by Zeke Hausfather
There has been much discussion of temperature adjustment of late in both climate blogs and in the media, but not much background on what specific adjustments are being made, why they are being made, and what effects they have. Adjustments have a big effect on temperature trends in the U.S., and a modest effect on global land trends. The large contribution of adjustments to century-scale U.S. temperature trends lends itself to an unfortunate narrative that “government bureaucrats are cooking the books”.
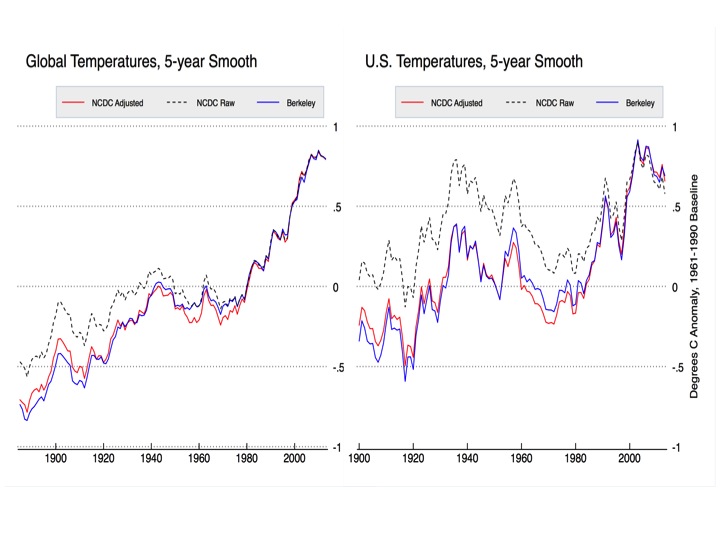
Figure 1. Global (left) and CONUS (right) homogenized and raw data from NCDC and Berkeley Earth. Series are aligned relative to 1990-2013 means. NCDC data is from GHCN v3.2 and USHCN v2.5 respectively.
Having worked with many of the scientists in question, I can say with certainty that there is no grand conspiracy to artificially warm the earth; rather, scientists are doing their best to interpret large datasets with numerous biases such as station moves, instrument changes, time of observation changes, urban heat island biases, and other so-called inhomogenities that have occurred over the last 150 years. Their methods may not be perfect, and are certainly not immune from critical analysis, but that critical analysis should start out from a position of assuming good faith and with an understanding of what exactly has been done.
This will be the first post in a three-part series examining adjustments in temperature data, with a specific focus on the U.S. land temperatures. This post will provide an overview of the adjustments done and their relative effect on temperatures. The second post will examine Time of Observation adjustments in more detail, using hourly data from the pristine U.S. Climate Reference Network (USCRN) to empirically demonstrate the potential bias introduced by different observation times. The final post will examine automated pairwise homogenization approaches in more detail, looking at how breakpoints are detected and how algorithms can tested to ensure that they are equally effective at removing both cooling and warming biases.
Why Adjust Temperatures?
There are a number of folks who question the need for adjustments at all. Why not just use raw temperatures, they ask, since those are pure and unadulterated? The problem is that (with the exception of the newly created Climate Reference Network), there is really no such thing as a pure and unadulterated temperature record. Temperature stations in the U.S. are mainly operated by volunteer observers (the Cooperative Observer Network, or co-op stations for short). Many of these stations were set up in the late 1800s and early 1900s as part of a national network of weather stations, focused on measuring day-to-day changes in the weather rather than decadal-scale changes in the climate.
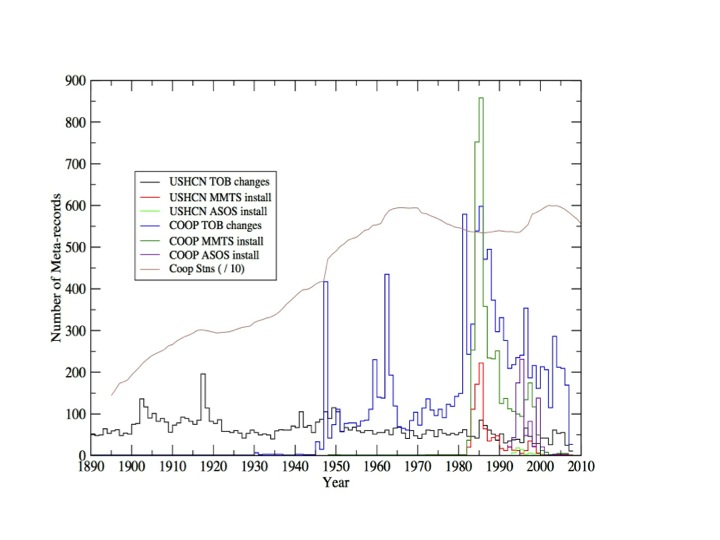
Figure 2. Documented time of observation changes and instrument changes by year in the co-op and USHCN station networks. Figure courtesy of Claude Williams (NCDC).
Nearly every single station in the network in the network has been moved at least once over the last century, with many having 3 or more distinct moves. Most of the stations have changed from using liquid in glass thermometers (LiG) inStevenson screens to electronic Minimum Maximum Temperature Systems(MMTS) or Automated Surface Observing Systems (ASOS). Observation times have shifted from afternoon to morning at most stations since 1960, as part of an effort by the National Weather Service to improve precipitation measurements.
All of these changes introduce (non-random) systemic biases into the network. For example, MMTS sensors tend to read maximum daily temperatures about 0.5 C colder than LiG thermometers at the same location. There is a very obvious cooling bias in the record associated with the conversion of most co-op stations from LiG to MMTS in the 1980s, and even folks deeply skeptical of the temperature network like Anthony Watts and his coauthors add an explicit correction for this in their paper.

Figure 3. Time of Observation over time in the USHCN network. Figure from Menne et al 2009.
Time of observation changes from afternoon to morning also can add a cooling bias of up to 0.5 C, affecting maximum and minimum temperatures similarly. The reasons why this occurs, how it is tested, and how we know that documented time of observations are correct (or not) will be discussed in detail in the subsequent post. There are also significant positive minimum temperature biases from urban heat islands that add a trend bias up to 0.2 C nationwide to raw readings.
Because the biases are large and systemic, ignoring them is not a viable option. If some corrections to the data are necessary, there is a need for systems to make these corrections in a way that does not introduce more bias than they remove.
What are the Adjustments?
Two independent groups, the National Climate Data Center (NCDC) and Berkeley Earth (hereafter Berkeley) start with raw data and use differing methods to create a best estimate of global (and U.S.) temperatures. Other groups like NASA Goddard Institute for Space Studies (GISS) and the Climate Research Unit at the University of East Anglia (CRU) take data from NCDC and other sources and perform additional adjustments, like GISS’s nightlight-based urban heat island corrections.

Figure 4. Diagram of processing steps for creating USHCN adjusted temperatures. Note that TAvg temperatures are calculated based on separately adjusted TMin and TMax temperatures.
This post will focus primarily on NCDC’s adjustments, as they are the official government agency tasked with determining U.S. (and global) temperatures. The figure below shows the four major adjustments (including quality control) performed on USHCN data, and their respective effect on the resulting mean temperatures.
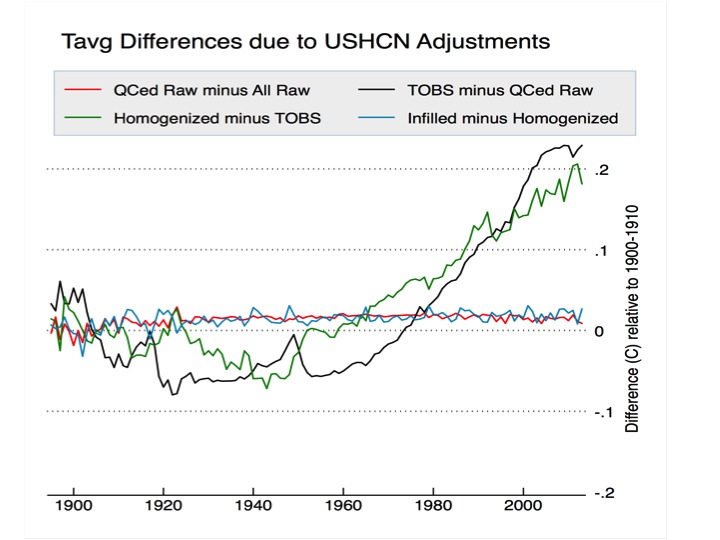
Figure 5. Impact of adjustments on U.S. temperatures relative to the 1900-1910 period, following the approach used in creating the old USHCN v1 adjustment plot.
NCDC starts by collecting the raw data from the co-op network stations. These records are submitted electronically for most stations, though some continue to send paper forms that must be manually keyed into the system. A subset of the 7,000 or so co-op stations are part of the U.S. Historical Climatological Network (USHCN), and are used to create the official estimate of U.S. temperatures.
Quality Control
Once the data has been collected, it is subjected to an automated quality control (QC) procedure that looks for anomalies like repeated entries of the same temperature value, minimum temperature values that exceed the reported maximum temperature of that day (or vice-versa), values that far exceed (by five sigma or more) expected values for the station, and similar checks. A full list of QC checks is available here.
Daily minimum or maximum temperatures that fail quality control are flagged, and a raw daily file is maintained that includes original values with their associated QC flags. Monthly minimum, maximum, and mean temperatures are calculated using daily temperature data that passes QC checks. A monthly mean is calculated only when nine or fewer daily values are missing or flagged. A raw USHCN monthly data file is available that includes both monthly values and associated QC flags.
The impact of QC adjustments is relatively minor. Apart from a slight cooling of temperatures prior to 1910, the trend is unchanged by QC adjustments for the remainder of the record (e.g. the red line in Figure 5).
Time of Observation (TOBs) Adjustments
Temperature data is adjusted based on its reported time of observation. Each observer is supposed to report the time at which observations were taken. While some variance of this is expected, as observers won’t reset the instrument at the same time every day, these departures should be mostly random and won’t necessarily introduce systemic bias. The major sources of bias are introduced by system-wide decisions to change observing times, as shown in Figure 3. The gradual network-wide switch from afternoon to morning observation times after 1950 has introduced a CONUS-wide cooling bias of about 0.2 to 0.25 C. The TOBs adjustments are outlined and tested in Karl et al 1986 and Vose et al 2003, and will be explored in more detail in the subsequent post. The impact of TOBs adjustments is shown in Figure 6, below.
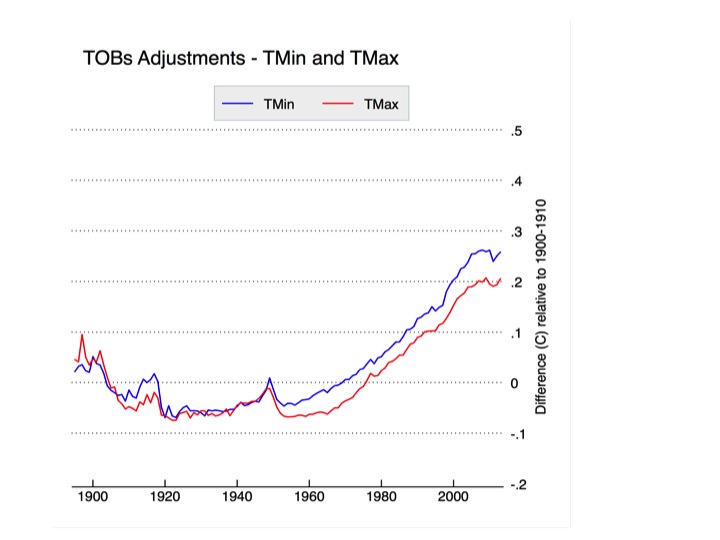
Figure 6. Time of observation adjustments to USHCN relative to the 1900-1910 period.
TOBs adjustments affect minimum and maximum temperatures similarly, and are responsible for slightly more than half the magnitude of total adjustments to USHCN data.
Pairwise Homogenization Algorithm (PHA) Adjustments
The Pairwise Homogenization Algorithm was designed as an automated method of detecting and correcting localized temperature biases due to station moves, instrument changes, microsite changes, and meso-scale changes like urban heat islands.
The algorithm (whose code can be downloaded here) is conceptually simple: it assumes that climate change forced by external factors tends to happen regionally rather than locally. If one station is warming rapidly over a period of a decade a few kilometers from a number of stations that are cooling over the same period, the warming station is likely responding to localized effects (instrument changes, station moves, microsite changes, etc.) rather than a real climate signal.
To detect localized biases, the PHA iteratively goes through all the stations in the network and compares each of them to their surrounding neighbors. It calculates difference series between each station and their neighbors (separately for min and max) and looks for breakpoints that show up in the record of one station but none of the surrounding stations. These breakpoints can take the form of both abrupt step-changes and gradual trend-inhomogenities that move a station’s record further away from its neighbors. The figures below show histograms of all the detected breakpoints (and their magnitudes) for both minimum and maximum temperatures.
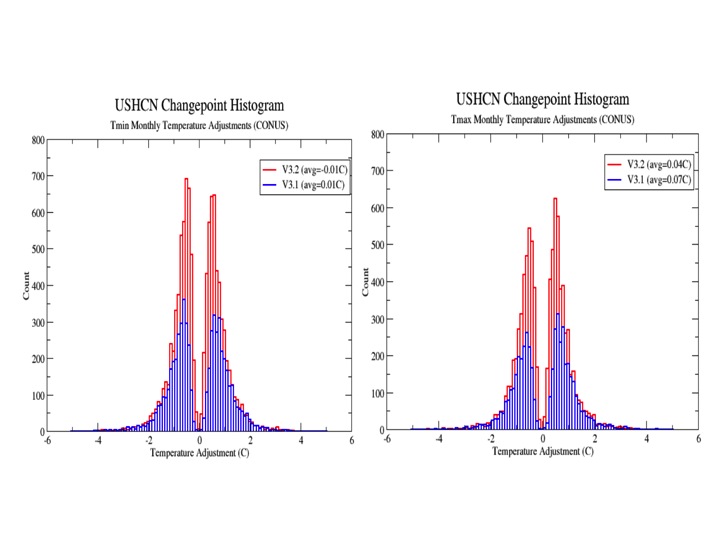
Figure 7. Histogram of all PHA changepoint adjustments for versions 3.1 and 3.2 of the PHA for minimum (left) and maximum (right) temperatures.
While fairly symmetric in aggregate, there are distinct temporal patterns in the PHA adjustments. The single largest of these are positive adjustments in maximum temperatures to account for transitions from LiG instruments to MMTS and ASOS instruments in the 1980s, 1990s, and 2000s. Other notable PHA-detected adjustments are minimum (and more modest maximum) temperature shifts associated with a widespread move of stations from inner city rooftops to newly-constructed airports or wastewater treatment plants after 1940, as well as gradual corrections of urbanizing sites like Reno, Nevada. The net effect of PHA adjustments is shown in Figure 8, below.

Figure 8. Pairwise Homogenization Algorithm adjustments to USHCN relative to the 1900-1910 period.
The PHA has a large impact on max temperatures post-1980, corresponding to the period of transition to MMTS and ASOS instruments. Max adjustments are fairly modest pre-1980s, and are presumably responding mostly to the effects of station moves. Minimum temperature adjustments are more mixed, with no real century-scale trend impact. These minimum temperature adjustments do seem to remove much of the urban-correlated warming bias in minimum temperatures, even if only rural stations are used in the homogenization process to avoid any incidental aliasing in of urban warming, as discussed in Hausfather et al. 2013.
The PHA can also effectively detect and deal with breakpoints associated with Time of Observation changes. When NCDC’s PHA is run without doing the explicit TOBs adjustment described previously, the results are largely the same (see the discussion of this in Williams et al 2012). Berkeley uses a somewhat analogous relative difference approach to homogenization that also picks up and removes TOBs biases without the need for an explicit adjustment.
With any automated homogenization approach, it is critically important that the algorithm be tested with synthetic data with various types of biases introduced (step changes, trend inhomogenities, sawtooth patterns, etc.), to ensure that the algorithm will identically deal with biases in both directions and not create any new systemic biases when correcting inhomogenities in the record. This was done initially in Williams et al 2012 and Venema et al 2012. There are ongoing efforts to create a standardized set of tests that various groups around the world can submit homogenization algorithms to be evaluated by, as discussed in our recently submitted paper. This process, and other detailed discussion of automated homogenization, will be discussed in more detail in part three of this series of posts.
Infilling
Finally we come to infilling, which has garnered quite a bit of attention of late due to some rather outlandish claims of its impact. Infilling occurs in the USHCN network in two different cases: when the raw data is not available for a station, and when the PHA flags the raw data as too uncertain to homogenize (e.g. in between two station moves when there is not a long enough record to determine with certainty the impact that the initial move had). Infilled data is marked with an “E” flag in the adjusted data file (FLs.52i) provided by NCDC, and its relatively straightforward to test the effects it has by calculating U.S. temperatures with and without the infilled data. The results are shown in Figure 9, below:
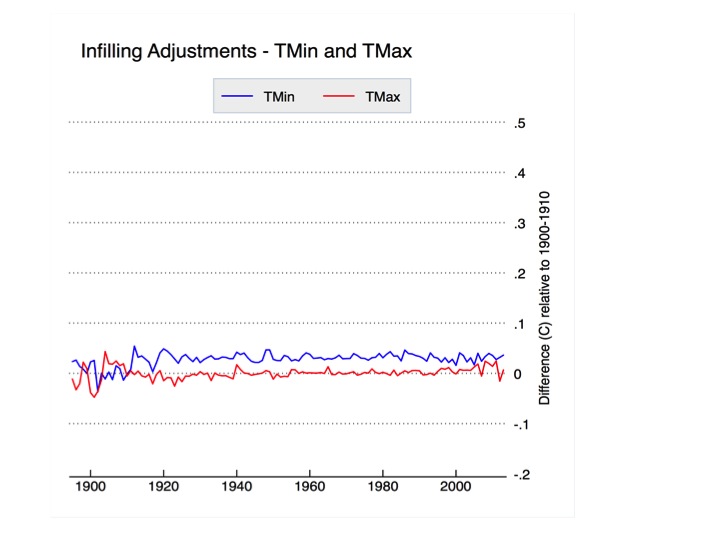
Figure 9. Infilling-related adjustments to USHCN relative to the 1900-1910 period.
Apart from a slight adjustment prior to 1915, infilling has no effect on CONUS-wide trends. These results are identical to those found in Menne et al 2009. This is expected, because the way NCDC does infilling is to add the long-term climatology of the station that is missing (or not used) to the average spatially weighted anomaly of nearby stations. This is effectively identical to any other form of spatial weighting.
To elaborate, temperature stations measure temperatures at specific locations. If we are trying to estimate the average temperature over a wide area like the U.S. or the Globe, it is advisable to use gridding or some more complicated form of spatial interpolation to assure that our results are representative of the underlying temperature field. For example, about a third of the available global temperature stations are in U.S. If we calculated global temperatures without spatial weighting, we’d be treating the U.S. as 33% of the world’s land area rather than ~5%, and end up with a rather biased estimate of global temperatures. The easiest way to do spatial weighting is using gridding, e.g. to assign all stations to grid cells that have the same size (as NASA GISS used to do) or same lat/lon size (e.g. 5×5 lat/lon, as HadCRUT does). Other methods include kriging (used by Berkeley Earth) or a distance-weighted average of nearby station anomalies (used by GISS and NCDC these days).
As shown above, infilling has no real impact on temperature trends vs. not infilling. The only way you get in trouble is if the composition of the network is changing over time and if you do not remove the underlying climatology/seasonal cycle through the use of anomalies or similar methods. In that case, infilling will give you a correct answer, but not infilling will result in a biased estimate since the underlying climatology of the stations is changing. Thishas been discussed at length elsewhere, so I won’t dwell on it here.
I’m actually not a big fan of NCDC’s choice to do infilling, not because it makes a difference in the results, but rather because it confuses things more than it helps (witness all the sturm und drang of late over “zombie stations”). Their choice to infill was primarily driven by a desire to let people calculate a consistent record of absolute temperatures by ensuring that the station composition remained constant over time. A better (and more accurate) approach would be to create a separate absolute temperature product by adding a long-term average climatology field to an anomaly field, similar to the approach that Berkeley Earth takes.
Changing the Past?
Diligent observers of NCDC’s temperature record have noted that many of the values change by small amounts on a daily basis. This includes not only recent temperatures but those in the distant past as well, and has created some confusion about why, exactly, the recorded temperatures in 1917 should change day-to-day. The explanation is relatively straightforward. NCDC assumes that the current set of instruments recording temperature is accurate, so any time of observation changes or PHA-adjustments are done relative to current temperatures. Because breakpoints are detected through pair-wise comparisons, new data coming in may slightly change the magnitude of recent adjustments by providing a more comprehensive difference series between neighboring stations.
When breakpoints are removed, the entire record prior to the breakpoint is adjusted up or down depending on the size and direction of the breakpoint. This means that slight modifications of recent breakpoints will impact all past temperatures at the station in question though a constant offset. The alternative to this would be to assume that the original data is accurate, and adjusted any new data relative to the old data (e.g. adjust everything in front of breakpoints rather than behind them). From the perspective of calculating trends over time, these two approaches are identical, and its not clear that there is necessarily a preferred option.
Hopefully this (and the following two articles) should help folks gain a better understanding of the issues in the surface temperature network and the steps scientists have taken to try to address them. These approaches are likely far from perfect, and it is certainly possible that the underlying algorithms could be improved to provide more accurate results. Hopefully the ongoing International Surface Temperature Initiative, which seeks to have different groups around the world send their adjustment approaches in for evaluation using common metrics, will help improve the general practice in the field going forward. There is also a week-long conference at NCAR next week on these issues which should yield some interesting discussions and initiatives.









{kind=link}
The author says there is no such thing as a pure and unadulterated temperature reading. Does this apply to the Central England Temperature record which I understand is a well regarded record of temperatures since the 1600s. I have a particular and arguably proprietorial, interest in this as I come from Central England and would like to have something to skite about.
Hi ryland,
The Central England Temperature record is an amalgation of multiple stations, and is subject to time of observation adjustments, instrument change adjustments, station move adjustments, and others. See this paper by Parker et al for example: http://www.metoffice.gov.uk/hadobs/hadcet/Parker_etalIJOC1992_dailyCET.pdf
Mercury thermometers weren't even invented to the early 1700s, so data before that is tough to accurately interpret.
[PS] Fixed link
So, you expect me to believe that temperature adjustments are honest as opposed to a nefarious plot by a global conspiracy involving 97% of the climate scientists in the world all bent on
I think not!
[DB] Please make it clear if you are using sarcasm, as Poe's Law is easy to transgress.
Hi Zeke, I really enjoyed reading this, thank you. Look forward to your other two posts.
Temp homogenisations are not only discussed on the mainstream blogs, but also in the backwaters. I'm not able to provide answers to the many questions which 'sceptics' have on this issue, but if you had time you might be able to set at least one of them straight :)
http://euanmearns.com/re-writing-the-climate-history-of-iceland/
Hi Kit,
Iceland is an interesting case. NCDC adjusts the mid-century warming down significantly, while Berkeley does not. As Kevin Cowtan has discussed, homogenization may make mistakes when there are geographically isolated areas with sharp localized climate changes (e.g. parts of the Arctic in recent years, and perhaps in Iceland back in the mid-century). For more see his discussion here: http://www-users.york.ac.uk/~kdc3/papers/coverage2013/update.140404.pdf
I don't have the expertise on Iceland's specific record to tell you which one is correct; either way, however, the impact on global temperatures (which is primarly the metric we care about) is fairly negligable.
Following figure 2: "Observation times have shifted from afternoon to morning at most stations since 1960, as part of an effort by the National Weather Service to improve precipitation measurements."
How does taking the observations in the morning improve precipitation measurements? Is there a pattern in the diurnal timing of precipitation in the US? Thanks in advance.
Hi DAK4,
As far as I'm aware the reason why morning readings of rain gauges was preferred was to minimize the amount of daytime evaporation.
I'm curious too. If you only read the station once a day, then I dont see how this helps, unless you get more rain at night/late pm. Morning rain would evaporate in the afternoon.
Zeke, many thanks!
ryland, the Central England Temperature record is about as far from a "pure and unadulterated temperature reading" as you can get. For example, the values for the early decades are essentially guesses based on descriptions of the weather in old letters... if people wrote that it was a hot summer or that a river stayed frozen longer than normal then the estimated 'temperature' value for that year was adjusted up or down accordingly.
This is not to say that's 'bad'... it's the best data available, but the idea that the CET is in any way 'more accurate' than other temperature records is just not valid.
Zeke, Your Fig. 1 for "Global" shows adjustments to give more warming. Do you mean "Global Land" there? I though adjustments to ocean temps lead to LESS warming globally. That would be the bottom line. End of discussion. Those "leftist" scientists fudge to show LESS warming.
Sailingfree,
Figure 1 does indeed show land only. Here is what land/ocean looks like: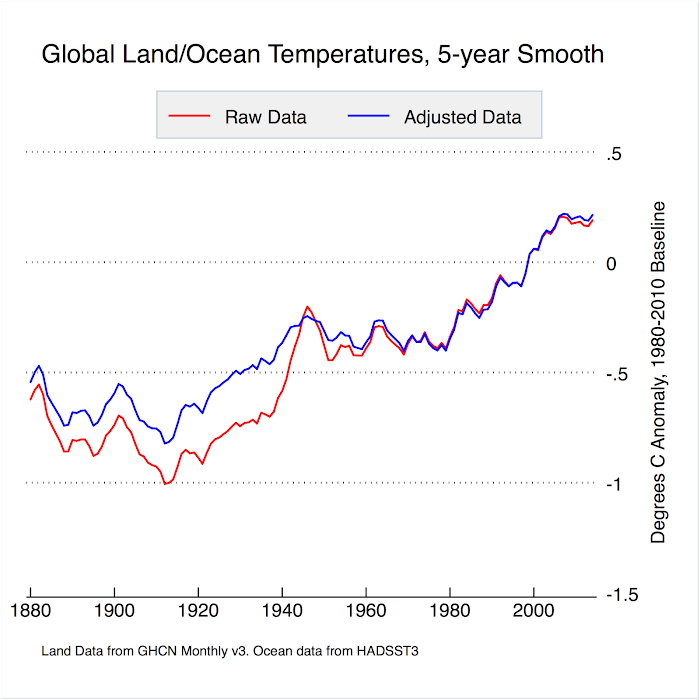
[RH] Adjusted image size to fit page formatting.
Some of the "other" known problems with the earlier portions of the Central England Temperature (CET) record include the taking of some readings indoors , and the use of records from Utrecht, NL, to fill in time gaps, meaning some portions are not even from central England.
Thanks, this is very helpful. Perhaps you could add that the article was originally published last July on Judith Curry's blog and engendered a long long comment thread. Have there been changes in it since then?
[best also to remove the reference to the "upcoming" NCAR conference]
Thanks very much to all for the info on CET, it is much appreeciated. A note for the diaries. If, in due course, climate sceptics say the Spring of 2015 in the UK was unusually cool it may be because the first day of Spring has, this year, been moved to March 1 from the long standing March 21. On a more serious note, thinking about what seems a significant change to "Spring" in the UK, one can more readily appreciate the difficulties and problems involved in assessing temperatures obtained over many decades from a myriad of sources.
I have just read two pieces by Graham Lloyd in The Australian (February 28) stating that the BoM has questions to answer about the change in temperatufre records and that an independent assessment panel has been set up to look at ACORN-SAT. It is claimed that the BoM removed 57 stations from its calculations replacing them with 36 on-avreage hotter stations and that this has created an increase of 0.42C in the recorded Australian average temperature independently of any actual real change in temperature. Pieces such as these in The Australian and similar pieces in the UK's Sunday Telegraph, are widely read and add significantly to the scepticism about the reality of human iinduced temperature change. I
I expect that's kind of the point of these reality-challenged newspaper opinion pieces - to convince people something isn't happening when it is. Even without the land surface temperature record, we know that global sea level is rising and worldwide loss of land-based ice is accelerating. So very clearly the world is warming. A lot.
But the real point Rob Painting is that very few people are going to read either your comments or my comments while several tens of thousands and possibly a hundred thousand or more will read the pieces in the Australian and the Telegraph. As the Australian piece is quoting emails in what it refers to as "Climategate" that don't portray the scientists involved in a very good light, the majority of the readers may well consider global warming to be something less than it really is.
Of course. This misinformation likely plays a big part in the lack of climate policy action. But this is definitely the wrong thread to continue this discussion.
Excellent article. Will you be addressing the status of metadata in the climate records and how this influences adjustments? After reading the Harry_readme file of climategate fame, I have the impression that at least some climate records have incomplete, confusing, and perhaps incorrect metadata. I have also read that older records (pre 70s) generally have little or no metadata associated with them. I would appreciate any information you could provide about this issue.
Also, are any of the raw climate records with metadata available online? It would be interesting to me to see at least a small sample. I have done analysis of microarray data for quantifying gene expression for over 40,000 genes and these data generally require normalization due to quirks of the fluorescence readers and the microarrrays, so I understand that it is sometimes necessary to adjust data. However, most journals that publish microarray data require the results and a description of the normalization method to be placed in a public database before the paper can be published. Wouldn't something like that be useful for enhanced credibility in climate science?
ryland @16, with regard to the claims made in The Australian, several of them are certainly false. Thus Graham Lloyd writes:
However, the various teams generating global temperature series independently access the raw data from their own choice of stations. Therefore, selection of stations used by the BoM has no bearing on those global temperature records.
That fact also means those global records can be used as an independent check on the ACORN-SAT method, something done by the BoM as part of the review of the independent peer review of ACORN-SAT. Of most interest is the comparison with BEST, not made in that review. BEST, like ACORN-SAT shows a 0.9 C warming from 1910 to current. That is interesting because BEST leaves out no records. So whether you use 686 current, and 821 former stations (BEST) or 112 stations choses for their high quality and largely continuous record (ACORN-SAT), you get essentially the same result.
That in turn means that if stations left out of the ACORN-SAT network make a difference to the trend, they were left out for good reason, ie, that station moves, change of equipment or changes in station surroundings have rendered those stations poor records of centenial change.
ryland
"It is claimed that the BoM removed 57 stations from its calculations replacing them with 36 on-avreage hotter stations and that this has created an increase of 0.42C in the recorded Australian average temperature independently of any actual real change in temperature."
And in this Graham Lloyd highlights that he doesn't understand how temperature trends are calculated. Just substituting warmer stations doesn't necesarily increase the trend. One actually would need to substitute warming stations to manipulate the trend.
This harks back to claims some years ago about the dropping of high latitude stations in Canada from the analysis, implying that since they were from a colder region, this would bias the trend higher. When in fact, since the fastest warming in the world is happening in the Arctic, if dropping stations from there were to have any impact (it doesn't by the way, there is still enough coverage) it would actually lower the trend.
Glenn Tamblyn @22, I think that is just poor wording by Lloyd, ie, that the claim is that not using those stations increases the trend. Unfortunately I have been unable to find a more detailed exposition of the claim to confirm that, or to find a list of the stations purportedly excluded. In fact, all I have found is a powerpoint presentation of Stockwell's more general critique of ACORN-SAT which proves he is just another denier. The proof is in his running the argument that the difference in rate of positive and negative adjustments between different time periods proves there is something wrong, without noting tha the algorithms used in homogenization do not factor in the decade of the adjustment, and therefore logically cannot be biased in the way he claims.
Tom
" I think that is just poor wording by Lloyd"
Not so sure. In terms of his personal understanding of the temperature record is concerned it may simply reflect his ignorance - and enthusiasm for promoting a message. But it plays to a deeper misunderstanding.
I suspect most people who think about how temperature record calculations are done can easily fall into the trap of thinking that adding/removing warm stations/cold stations will automatically bias the calculation.
They don't get the difference between the Anomaly of the Averages, and the Average of the Anomalies.
So dropping/adjusting stations can seem far more significant than it actually is.
That's why this particular zombie just keeps on walking. And every time someone waves a voodoo wand at it again to keep it moving a whole new audience can be left scratching their heads - 'yeah, sure looks reasonable to me'.
Tom Curtis and Glenn Tamblyn In view of Rob Paintings's comment @ 19 I had not intended to write further on this but I do think the level of naivety in your posts, particularly that from Tom Curtis, does need addressing. Those writing the articles know exactly the audience they wish to reach and write accordingly. Graham Lloyd almost certainly didn't give a hoot about his wording he just wanted to get a simple message across and so used simple language. Similarly most readers of these pieces neither know of or care about anomalies. They just look at the simplistic analyses presented and as you state say "yeah looks reasonable to me" This statistic might give you cause for pause, the article by Christopher Booker in the Telegraph got 31,758 comments. The title of the piece was "The fiddling of temperature data is the biggest science scandal ever" In contrast this piece at SkS has 24 to date. One thing that does damage climate scientists cause are statements such as "2014 was the hottest year ever" which then has to be modified in view of the margins of error. The Daily Mail, whatever you may think of this paper it does have a very wide circulation, does know its audience and made Gavin Schmidt look a charlatan (http://tinyurl.com/lsr87rg). Unlike the MSM, connecting with the "man in the street" does not seem the forte of those promoting the dangers of human caused climate change.
[JH] You are skating on the thin ice of sloganeering which is prohibited by the SkS Comments Policy.
Please note that posting comments here at SkS is a privilege, not a right. This privilege can be rescinded if the posting individual treats adherence to the Comments Policy as optional, rather than the mandatory condition of participating in this online forum.
Please take the time to review the policy and ensure future comments are in full compliance with it. Thanks for your understanding and compliance in this matter.
Ryland, I'm surprised that you start your post describing accurately some newspapers' attitudes then ends by chiding scientists for not including the margin of error. Seems you're the one being naive. The only thing doing damage to climate scientists is to be targeted by despicable people who will back at nothing to undermine the public's understanding of science. The silly talk about margin of error is laughable coming from the clowns who keep saying that it hasn't warmed since 1998 or that there is a pause. Let's start there for statistical accuracy why don't we? But the media never calls this kind of BS a "scandal" do they?
The real problem of climate scientists comes from the stooges willing to organise harassment campaigns, steal e-mails to twist their meaning, threaten them with physical violence, use every dirty trick in the book with no regard whatsoever for any kind of intellectual honesty or scientific accuracy. The real problem comes from media outlets that are used to foster the ideological agenda of their owner and manipulate peope's minds without any scruples or regard for such details as physical reality. The real problem is that scientific illiteracy is so deep and prevalent that a buffoon like Monckton can manage to attract attention with his delirious ramblings and gather more credibility than those who know what they're talking about. That's the real problem. There is no other.
Regardless what they do, climate scientists are damned. There is no debate with people like that. It's like being on trial with Staline as the judge. They're only out to silence you and they'll stop at nothing so long as they are reasonably sure they'll get away with it. Margin of error? Give me a break.
Ryland @25 - It may interest you to learn that according to The Sunday Telegraph's Head of Editorial Compliance:
[Christopher Booker’s article] is clearly an opinion article and identifiable as such.
http://GreatWhiteCon.info/2015/02/a-letter-to-the-editor-of-the-sunday-telegraph/#Feb20
Furthermore we also have proof positive that David Rose simply makes stuff up for his articles in The Mail on Sunday:
http://GreatWhiteCon.info/2014/08/has-the-arctic-ice-cap-expanded-for-the-second-year-in-succession/#Feb03
If you have any further questions (that conform to the SkS comments policy) then please do not hesitate to ask!
@Ryland
Nice segue from a seemingly innocent comment about the CET in #1 to letting rip with some blatant ideology in #25.
I would like to ask a straightforward question: When you're reading articles by the likes of LLoyd, Booker or Rose, does it ever occur to you to actually employ some genuine scepticism, or does every word they write simply get accepted at face value? (Since you hail from the CET area, I'm sure you won't mind if I spell "scepticism" without the increasingly ubiquitous "k".)
Since you seem to have a bee in the bonnet regarding error margins, here's a little trick - meaning technique or procedure - which you may care to try out some time...
Pick any of the main global temperature datsets (UAH, RSS, Gistemp, HadCRUT, NCDC or BEST) and work out the most recent half dozen or so pentadal (5-year) averages. (i.e. 2010-2014, 2005-2009, 2000-2005, 1995-1999,1990-1995,1985-1989)
Notice any underlying trends there?
As the periods of interest are now 60 months long - rather than just 12 - the associated uncertainties will have decreased. Kevin Cowtan wrote an article on this matter about 3 years ago describing the SkS temperature trend calculator. Perhaps you should peruse this before digging a deeper hole for yourself.
David Rose making Gavin Schmidt look like a charlatan? - Pot, Kettle, Black!
"This statistic might give you cause for pause, the article by Christopher Booker in the Telegraph got 31,758 comments. The title of the piece was "The fiddling of temperature data is the biggest science scandal ever" In contrast this piece at SkS has 24 to date."
That would still mean this SkS thread has roughly twice the number of substantive comments as the Telegraph article.
My apologies to all for my inability to express myself in a manner that makes my stance clear. My comments at 25 were directed at the MSM appealing to the man in the street and are not, repeat not, me having a go at Gavin Schmidt. I thought, obviously incorrectly, that my comment "The Daily Mail, whatever you may think of this paper it does have a very wide circulation, does know its audience and made Gavin Schmidt look a charlatan" made it clear that it was not me but headline in The Daily Mail making Gavin Schmidt appear a charlatan. Personally I know what margins of error are but does the "man in the street"? The point I obviously didn't make is that columnists know how to get their message across, after all it is their job, and no I certainly don't accept every word these journalists write. Nor did I chide Gavin Schmidt on margins of error, I was pointing out that that is what David Rose in the Daily Mail did. I agree it is a privilege to post here and have no wish to lose it. I obviously need to make it much clearer than I have done in 25 above, which are my own thoughts and which are the thoughts of others. In a nutshell I think, and this is a personal think, that the sceptical MSM is winning the debate on human induced climate change. This could be because the papers that "the masses" read don't want opinion pieces from climate scientists and/or that the language used in op-eds and other publications from climate scientists does not resonate with "the man in the street"
@ Zeke,
Thanks for the illuminating piece, I look forward to reading parts II & III.
In the PHA section, you briefly mention Reno, and this has triggered some - possibly false - memory. A nagging little voice (Aside to the wife: No, not you dear!) keeps telling me that I've read that the UHI adjustment for Remo is somewhere in the order of 11o C.
Does that sound about right, or shall I merely add it to the list of "things that I thought were real, but weren't"?
I suppose the same kind of problem exists in the wonderful world of phenology (not phrenology). Yet another article has appeared on the BBC discussing non-instumental indicators.
Cheers Bill F
ryland - Fortunately, with the exception of the usual suspects (Fox News, The Telegraph, the Australian, and so on), mainstream media appears to be taking climate change much more seriously.. Skeptics on talk shows, dimension of climate change comes more and more often in general news shows, etc.
It's my impression that the deniers are just becoming less and less credible.
Sorry, that last post should have said "_fewer_" skeptics on talk shows.
Ryland @30 - So we're agreed that the "sceptical MSM" just make stuff up that they think their audience would like to hear? That being the case, what should climate scientists do about that situation. Start making stuff up as well? Failing that, how should they alter their communications such that they start to "resonate with the man in the street"?
Ryland@30,
I agree with Jim Hunt's summation that you have been identifying the unacceptable behaviour in the MSM reporting regarding climate science. Unlike Jim, who asks what you believe climate scientists should do, I would ask why you expect that your comments here will change the unacceptable behaviour in the MSM that you are aware of.
The people who contribute to this site or frequently visits this site are probably well aware of the unacceptable behaviour of many reporters/opinion makers in the MSM as well as at other misleading sites. And it would be wonderful if a proper presentation of the actual facts of the matter could be provided as an introduction to every misleading report in the first posting of the misleading report, but that won't happen.
What can happen is the continued development of the best understanding of what is going on, not just the climate science, but also what is going on in the presentation of information to the public and how people who claim to be 'leaders' have actually been behaving. That is what this site, and many like it are all about.
Eventually the majority of the population will stop believing the misleading claim-making and the fraudulent 'leaders', realizing who the real trouble-makers are. That is the only future for humanity and that effective majority realization is already here (even in the Canada, USA, and Australia), but the trouble-makers are still able to deceptively maintain undeserved wealth accummulation and power (and abusive misleading marketing influence). However, their days are clearly as limited as the unsustainable damaging pursuits they strive to prolong with the small pool of support from people who can never be expected to give up their fight to get away with undeserved unsustainable and damaging desired actions.
'Every man on the street' does not need to be convinced. In fact, many of those people will never allow themselves to be convinced. The developing better understanding and progress of humanity toward a sustainable better futre for all will leave them bitterly disappointed, as they deserve to be, with their only real choice being to 'change their mind'. And the continued pursuit of the best understanding of what is going on is the key to making that happen.
@ Jim H & OPOF (#34 &35)
" ... many of those people will never allow themselves to be convinced"
Therein lies (pun intended) the rub. As most rational people will have long since realised, the so-called debate about global warming has nothing to do with science, or indeed with logical thought.
Much of the MSM is owned, body and soul, by oligarchs with a special (i.e. financial) interest in the maintenance of the status quo. (This is an instance where it could be quite understandable to mistakenly render the word "oligarch" as "oiligarch"!) As this section of the MSM tends to be aimed squarely at right-leaning viewers, readers and - ultimately - voters, the whole climate change denial meme has become subsumed into the collective ring-wing mindset.
I live in a small village next to Dartmoor National Park in the SW of England, and an overwhelming percentage of the populace are deeply conservative in their political opinions. The two best-selling newspapers at the local shop are - surprise, surprise - the Telegraph and the Mail.
The problem I experience in trying to introduce some sanity into any debate about AGW is that it is well-nigh impossible. Why? Because any attempt to rebut the seemingly never-ending stream of drivel from the likes of Rose or Booker (or Monkton or WUWT, etc., etc.) is instantly perceived as an attack on intrinsic Tory values. Any attempt to illuminate the matter by introducing unwelcome and inconvenient concepts such as actual facts (as opposed to made-up or cherry-picked varieties) just gets shrugged off by those warmly cocooned in the smug arrogance engendered by never stopping to question one's own beliefs.
On a personal level, the situation down in sunny Devon is exacerbated by the fact that, despite having spent 40-odd years south of the border, I still have a very pronounced Glaswegian accent. There are people with very strong anti-AGW sentiments living here who would gladly scoop out their own eyeballs with a rusty spoon, rather than admit that some jumped-up Satan-spawn from Red Clydeside knows more about the topic than someone - upon whose every word they hang - writing in their paper of choice.
However, leaving aside the parochial, the issue does actually run deeper. As mentioned before, this is not a genuine scientific disagreement over the interpretation of data. There are people in the MSM (and in many pseudo-science blogs) engaged in the dissemination of utter falsehoods. Eventually, they will stand trial at the bar of history - although personally, I'd much prefer that they stand trial in the conventional sense.
Eventually, the guff emanating from the likes of Booker and Rose will be shown up for what it is, and, for many, it will be a truly bitter pill to swallow. People will have to accept the fact that their deeply held views were, not simply wrong, but utterly nonsensical - and that much of the MSM was knowingly complicit in perpetrating a fraud of truly biblical proportions. People will be forced to look themselves in the mirror, and admit that they were played as a fool*, and that they cheerfully went along with it for years.
(* Although the Scots term "eedjit" is a far more apt descriptor.)
Few are going to have to cojones to admit this: many are just going to stuff their heads ever deeper in the sand. And as long as there are those prepared to buy their wares, the merchants of doubt will continue to spew forth their bile.
And on that cheerful note... awrabest Bill F
Bollocks!
Final paragraph above should have started...
"Few are going to have the cojones..."
Bill @36 - Since you're also from Devon you may well be interested in our latest exploration into the effects of the "sceptical MSM" on the psyches of a subset of the local population:
http://GreatWhiteCon.info/2015/03/arctic-basin-big-wave-surfing-contest-equipment-evaluation-1/
Click a link or two and you will quickly discover how we're currently in the process of hauling both The Mail and The Telegraph in front of of the shiny new "Independent" Press Standards Organisation. However I wouldn't go so far as to say that I'm optimistic the process will ultimately produce an outcome along the lines that OPOF suggests, i.e. "a proper presentation of the actual facts of the matter [that] could be provided as an introduction to every misleading report".
With a general election looming 38 Degrees are pretty active at the moment. What do you reckon to the idea of starting a petition against what Bob Ward of the Grantham Institute described as "A national scandal"?
https://twitter.com/ret_ward/status/384092857856176128
Comparing fig.1 (left) and trends on comment 12 it is clear that adjustment on the oceans during the first half of XX century has an opposite effect in comparison with adjustment on the lands.
Curiously this shows that raw data for land between 1910 and 1980 are similar to adjusted data for land+ocean.
Question: What specific instrumentation is used to measure global surface temps? ...and what percentage of all global temps are taken by NASA using the referenced sensors in the post below?
THe reason for asking is that I ran into a very belligerent and persistent denier who claims to work with a sensor that is very similar to the same that NASA uses and here are his claims in this post:
" NASA is on record stating that 2014 was the "hottest" on record since 1888. And 2014 was supposedly just 0.02 degrees C hotter than 2010 which is the next "hottest" year per NASA's dubious claim. Now, once again you stupid dunce! Platinum resistance temperature devices (P RTDs) are only accurate to +/- 0.1 degrees C from 0c to 150c, and +/- 0.15 degrees C from 0c to -30c per the IEC 60751 document. This is basic mathematical statistics your stupid head should have learned in high school. That is why when the lying director of the Goddard Institute of Space Science (GISS),(deleted text) Gavin Schmidt, is ON RECORD as stating that the claim of 2014 being the hottest was stated with just a 38% level of statistical certainty. I and others with a university level of mathematical education are not fooled by such a hokey statement, but Schmidt knowingly staked that claim so that gullible AGW drones like you would have something to eat up. It still amazes me that that there are buffoons like you that think anybody can derive a 0.02 C degree of precision from a device that is +/- 0.1 at best, not including the root mean sum squared addition value that the data acquisition electronics adds too it's error summation by about another one percent."
Above post is by Stefan_Z in a Yahoo comments section
I tried to steer the guy here to Zeke Hausfather's guest post , but to no avail...
Quick: If you have not already challenged your opponent to document all of his assertions, you should immediately do so.
Quick @40, suppose you have a single instrument with an accuracy of 0.1 C. Then for that station the best accuracy we can have is 0.1 C, and other factors may cause the error to be greater. However, if we want to determine the average temperature of 10 different sites, each using the same type of instrument, the error becomes the error of the average, ie, the square root of the additive sums of each error term, divided by the number of terms. For 10 sites, that turns out to be again 0.1 C. If we increase the number of sites to 100, the error margin, however, drops to 0.0316 (= ((0.1*100)^0.5)/100). With a thousand sites, it drops to 0.01. With 10 thousand sites it drops to 0.00316, and so on.
The USHCN has 1221 stations within the contiguous United States. The error on the simple average of that many stations assuming an instrumental error of 0.1 C is 0.009 C. The GHCN has around 2500 stations, yielding an accuracy for the simple average of 0.006 C. These figures are for the land only temperatures. On top of that there are thousands of SST measurements that go into the Global Mean Surface Temperature.
Clearly your denier's point is invalid. The quoted errors of the GMST are well above that which would be obtained from taking a simple mean. That extra is to account for other sources of error, the accounting of which has been detailed in peer reviewed papers.
FWIW I think a post specifically referencing the point Tom just made would be productive.
I've spent a lot of time in denierville and a regular assertion is 'You can't get temps/sea-level etc to 3 sig figures when instrumentation is barely accurate to the nearest degree.
Thanks Tom. Are the NASA sensors used only for US temps? If not, what other type of instrumentation is used by the GHCN and for SST measurements?
Quick @46, GISS (NASA) do not collect any thermometer records themselves. Rather they use the data collected by NOAA for the Global Historical Climate Network (GHCN), plus some additional stations in Antarctica an one additional station in Germany. In the US, the GHCN stations are just the US Historical Climate Network (USHCN) stations, with the data again collected by NOAA, and I believe much of it administered by NOAA. Elsewhere in the world, the data will come from various national meteorological stations.
As to which sensors are used, a whole host of different sensors both in different countries and within countries are used. All are approximately equivalent to thermometers in a Stevenson screen, but each will have their own error in measurement. GISS (and the NCDC) take that initial error rates and calculate from it the error in their overall temperature index using techniques similar to those I illustrated. It is not a simple as my illustration because not all instruments are the same, and the calculations are not taking simple averages. However, they are taking an average of a sort so that with a large number of station records, the error becomes a small fraction of the error of individual stations for reasons exactly related to those I illustrated.
The crucial point here is that denier you quote is ignoring the most fundamental fact about error propogation with respect to averages, while boasting of his great knowledge of the topic. His argument simply does not hold water. In contrast to his bombast, however, GISS, and the NCDC, and the Hadley Center and CRU teams, and the BEST team, and the JMA have all tackled these issues, worked out the error correctly, and published their methods and results in peer reviewed literature. And all five teams get essentially the same results with only slight divergences based on the data sets and methods used.
Quick, for more on Tom Curtis's explanation, look up the Law of Large Numbers.
Thanks again, Tom Curtis (and Tom Dayton)! I spent a copious amount of time trying to get info like this by simply Googling, but wasn't getting much...
Quick, a simple(istic) explanation of the Law of Large Numbers applied to this case is that each temperature measurement is a sample from the infinitely-sized population of all possible measurements of the "true" temperature value. Each measurement probably is erroneous in that probably it differs from the true temperature. But each measurement is randomly erroneous in direction and size from the true temperature, so a collection of those sample measurements will have some measurements' errors cancel out other measurements' errors. The probability of that collection of measurements completely cancelling its errors--and so revealing the true temperature--increases as the size of that collection grows. Therefore growing the size of the collection narrows the range of temperatures in which we can be "confident" the true temperature lies--no matter what probability/certainty you prefer as your definition of "confident." To use an example with less emotional baggage than global temperature, consider flipping a coin to find its true probability of coming up heads. The more trials you run (i.e., the more flips, the more measurements), the more likely that the averages of the numbers of flip results (heads vs. tails) are the "true" values.