






























 Arguments
Arguments





















Why Curry, McIntyre, and Co. are Still Wrong about IPCC Climate Model Accuracy
Posted on 4 October 2013 by dana1981
Earlier this week, I explained why IPCC model global warming projections have done much better than you think. Given the popularity of the Models are unreliable myth (coming in at #6 on the list of most used climate myths), it's not surprising that the post met with substantial resistance from climate contrarians, particularly in the comments on its Guardian cross-post. Many of the commenters referenced a blog post published on the same day by blogger Steve McIntyre.
McIntyre is puzzled as to why the depiction of the climate model projections and observational data shifted between the draft and draft final versions (the AR5 report won't be final until approximately January 2014) of Figure 1.4 in the IPCC AR5 report. The draft and draft final versions are illustrated side-by-side below.
I explained the reason behind the change in my post. It's due to the fact that, as statistician and blogger Tamino noted 10 months ago when the draft was "leaked," the draft figure was improperly baselined.
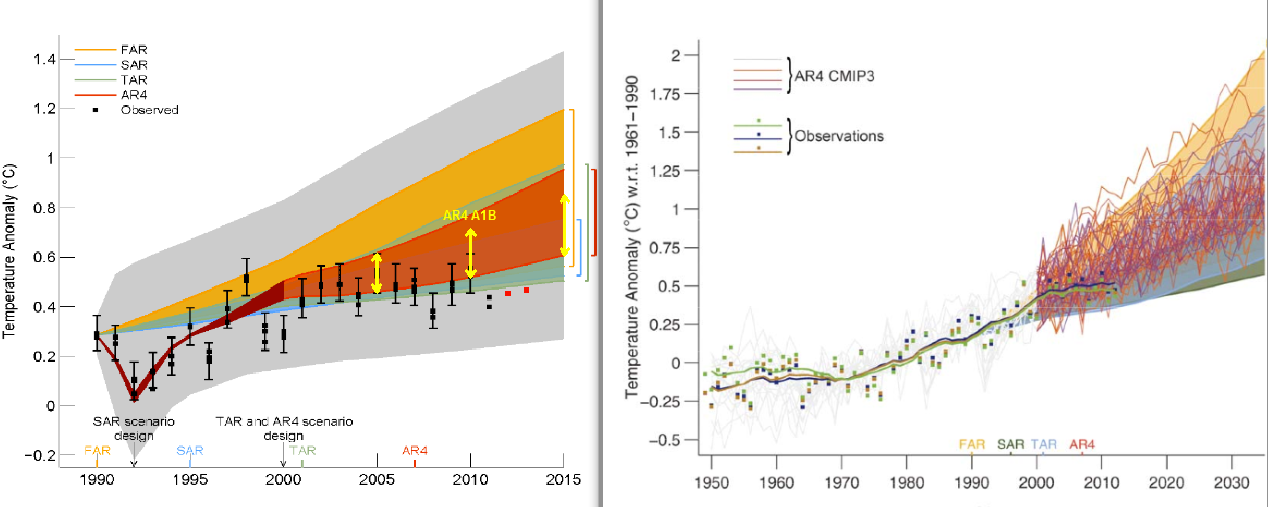
IPCC AR5 Figure 1.4 draft (left) and draft final (right) versions. In the draft final version, solid lines and squares represent measured average global surface temperature changes by NASA (blue), NOAA (yellow), and the UK Hadley Centre (green). The colored shading shows the projected range of surface warming in the IPCC First Assessment Report (FAR; yellow), Second (SAR; green), Third (TAR; blue), and Fourth (AR4; red).
What's Baselining and Why is it Important?
Global mean surface temperature data are plotted not in absolute temperatures, but rather as anomalies, which are the difference between each data point and some reference temperature. That reference temperature is determined by the 'baseline' period; for example, if we want to compare today's temperatures to those during the mid to late 20th century, our baseline period might be 1961–1990. For global surface temperatures, the baseline is usually calculated over a 30-year period in order to accurately reflect any long-term trends rather than being biased by short-term noise.
It appears that the draft version of Figure 1.4 did not use a 30-year baseline, but rather aligned the models and data to match at the year 1990. How do we know this is the case? Up to that date, 1990 was the hottest year on record, and remained the hottest on record until 1995. At the time, 1990 was an especially hot year. Consequently, if the models and data were properly baselined, the 1990 data point would be located toward the high end of the range of model simulations. In the draft IPCC figure, that wasn't the case – the models and data matched exactly in 1990, suggesting that they were likely baselined using just a single year.
Mistakes happen, especially in draft documents, and the IPCC report contributors subsequently corrected the error, now using 1961–1990 as the baseline. But Steve McIntyre just couldn't seem to figure out why the data were shifted between the draft and draft final versions, even though Tamino had pointed out that the figure should be corrected 10 months prior. How did McIntyre explain the change?
"The scale of the Second Draft showed the discrepancy between models and observations much more clearly. I do not believe that IPCC’s decision to use a more obscure scale was accidental."
No, it wasn't accidental. It was a correction of a rather obvious error in the draft figure. It's an important correction because improper baselining can make a graph visually deceiving, as was the case in the draft version of Figure 1.4.
Curry Chimes in – 'McIntyre Said So'
The fact that McIntyre failed to identify the baselining correction is itself not a big deal, although it doesn't reflect well on his math or analytical abilities. The fact that he defaulted to an implication of a conspiracy theory rather than actually doing any data analysis doesn't reflect particularly well on his analytical mindset, but a blogger is free to say what he likes on his blog.
The problem lies in the significant number of people who continued to believe that the modeled global surface temperature projections in the IPCC reports were inaccurate – despite my having shown they have been accurate and having explained the error in the draft figure – for no other reason than 'McIntyre said so.' This appeal to McIntyre's supposed authority extended to Judith Curry on Twitter, who asserted with a link to McIntyre's blog, in response to my post,
"No the models are still wrong, in spite of IPCC attempts to mislead."
In short, Curry seems to agree with McIntyre's conspiratorial implication that the IPCC had shifted the data in the figure because they were attempting to mislead the public. What was Curry's evidence for this accusation? She expanded on her blog.
"Steve McIntyre has a post IPCC: Fixing the Facts that discusses the metamorphosis of the two versions of Figure 1.4 ... Using different choices for this can be superficially misleading, but doesn’t really obscure the underlying important point, which is summarized by Ross McKitrick on the ClimateAudit thread"
Ross McKitrick (an economist and climate contrarian), it turns out, had also offered his opinion about Figure 1.4, with the same lack of analysis as McIntyre's (emphasis added).
"Playing with the starting value only determines whether the models and observations will appear to agree best in the early, middle or late portion of the graph. It doesn’t affect the discrepancy of trends, which is the main issue here. The trend discrepancy was quite visible in the 2nd draft Figure 1.4."
In short, Curry deferred to McIntyre's and McKitrick's "gut feelings." This is perhaps not surprising, since she has previously described the duo in glowing terms:
"Mr. McIntyre, unfortunately for his opponents, happens to combine mathematical genius with a Terminator-like relentlessness. He also found a brilliant partner in Ross McKitrick, an economics professor at the University of Guelph.
Brilliant or not, neither produced a shred of analysis or evidence to support his conspiratorial hypothesis.
Do as McKitrick Says, not as he Doesn't Do – Check the Trends
In his comment, McKitrick actually touched on the solution to the problem. Look at the trends! The trend is essentially the slope of the data, which is unaffected by the choice of baseline.
Unfortunately, McKitrick was satisfied to try and eyeball the trends in the draft version of Figure 1.4 rather than actually calculate them. That's a big no-no. Scientists don't rely on their senses for a reason – our senses can easily deceive us.
So what happens if we actually analyze the trends in both the observational data and model simulations? That's what I did in my original blog post. Tamino has helpfully compared the modeled and observed trends in the figure below.
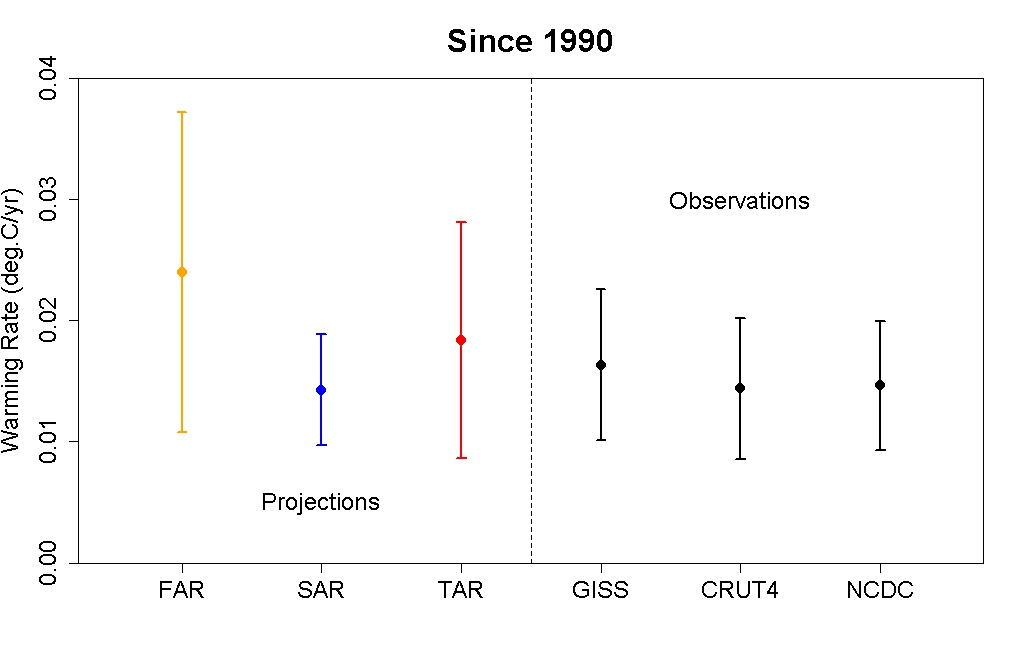
Global mean surface temperature warming rates and uncertainty ranges for 1990–2012 based on model projections used in the IPCC First Assessment Report (FAR; yellow), Second (SAR; blue), and Third (TAR; red) as compared to observational data (black). Created by Tamino.
The observed trends are entirely consistent with the projections made by the climate models in each IPCC report. Note that the warming trends are the same for both the draft and draft final versions of Figure 1.4 (I digitized the graphs and checked). The only difference in the data is the change in baselining.
This indicates that the draft final version of Figure 1.4 is more accurate, since consistent with the trends, the observational data falls within the model envelope.
Asking the Wrong (Cherry Picked) Question
Unlike weather models, climate models actually do better predicting climate changes several decades into the future, during which time the short-term fluctuations average out. Curry actually acknowledges this point.
This is good news, because with human-caused climate change, it's these long-term changes we're predominantly worried about. Unfortunately, Curry has a laser-like focus on the past 15 years.
"What is wrong is the failure of the IPCC to note the failure of nearly all climate model simulations to reproduce a pause of 15+ years."
This is an odd statement, given that Curry had earlier quoted the IPCC discussing this issue prominently in its Summary for Policymakers:
"Models do not generally reproduce the observed reduction in surface warming trend over the last 10 –15 years."
The observed trend for the period 1998–2012 is lower than most model simulations. But the observed trend for the period 1992–2006 is higher than most model simulations. Why weren't Curry and McIntyre decrying the models for underestimating global warming 6 years ago?
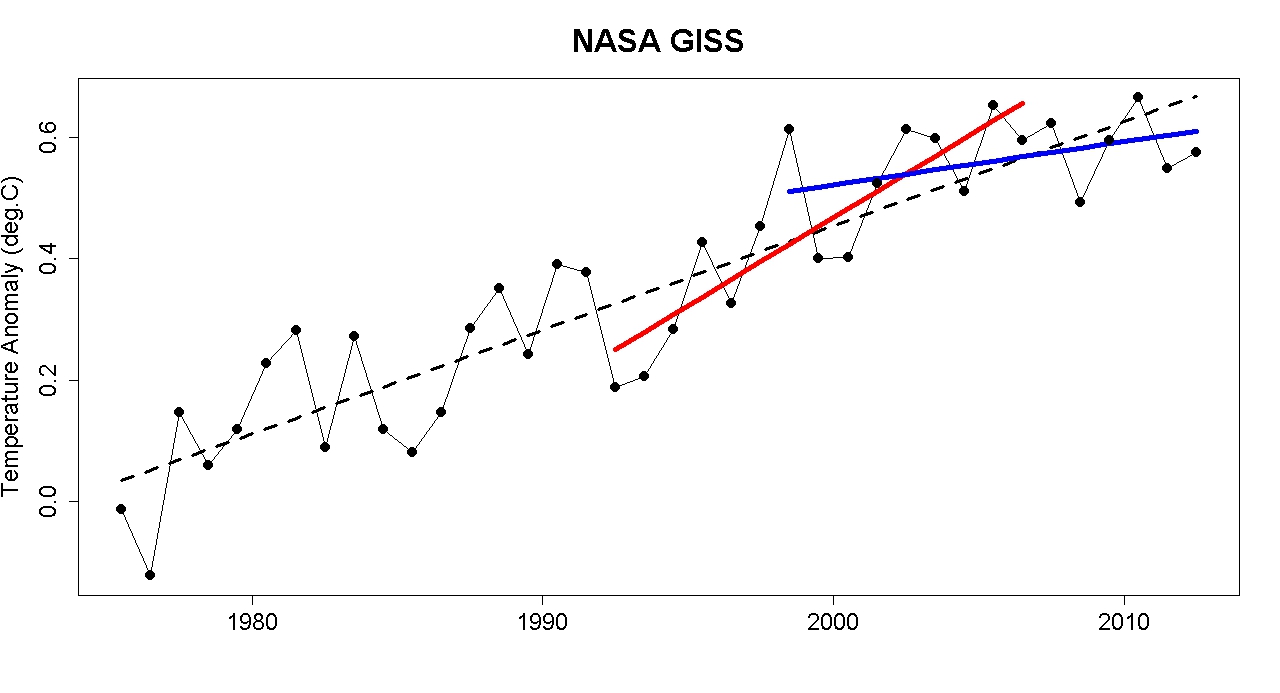
Global surface temperature data 1975–2012 from NASA with a linear trend (black), with trends for 1992–2006 (red) and 1998–2012 (blue). Created by Tamino.
This suggests that perhaps climate models underestimate the magnitude of the climate's short-term internal variability. Curry believes this is a critical point that justifies her conclusion "climate models are just as bad as we thought." But as the IPCC notes, the internal variability on which Curry focuses averages out over time.
"The contribution [to the 1951–2010 global surface warming trend] ... from internal variability is likely to be in the range of −0.1°C to 0.1°C."
While it would be nice to be able to predict ocean cycles in advance and better reproduce short-term climate changes, we're much more interested in long-term changes, which are dominated by human greenhouse gas emissions. And which, as Curry admits, climate models do a good job simulating.
It's also worth looking back at what climate scientists were saying about the rapid short-term warming trend in 2007. Rahmstorf et al. (2007), for example, said (emphasis added):
"The global mean surface temperature increase (land and ocean combined) in both the NASA GISS data set and the Hadley Centre/Climatic Research Unit data set is 0.33°C for the 16 years since 1990, which is in the upper part of the range projected by the IPCC ... The first candidate reason is intrinsic variability within the climate system."
Data vs. Guts
Curry and Co. deferred to McIntyre and McKitrick's gut feelings about Figure 1.4, and both of their guts were wrong. Curry has also defaulted to her gut feeling on issues like global warming attribution, climate risk management, and climate science uncertainties. Despite her lack of expertise on these subjects, she is often interviewed about them by journalists seeking to "balance" their articles with a "skeptic" perspective.
Here at Skeptical Science, we don't ask our readers to rely on our gut feelings. We strive to base all of our blog posts and myth rebuttals on peer-reviewed research and/or empirical data analysis. Curry, McIntyre, and McKitrick have failed to do the same.
When there's a conflict between two sides where one is based on empirical data, and the other is based on "Curry and McIntyre say so," the correct answer should be clear. The global climate models used by the IPCC have done a good job projecting the global mean surface temperature change since 1990.









SASM @ 133,
I think we all understand that this type of comparison isn’t meaningful in the initial stages of the forecast. But, as time advances forward the min/max trend lines become wider, and once they are as wide as the noisy temperature data, then the location of the origin really shouldn’t matter. For example, in your chart @126, you can see that the min/max trend lines are outside the 2.5%/97.5% model bands by 2013 or 2014.
Nevertheless, in both my chart and yours, it is clear that global temperatures are at the very low end of the model projections. You show the +/-2.5% bands and the current HADCRUT4 data is touching the lower 2.5% band. I read that as there was only a 2.5% chance that the global temperature would reach this level.
This is circular reasoning/begging the question. You're claiming that as time moves forward the min/max trend lines behave more and more like temperature bands, then use the observation that the temperature data is touching the lower 2.5% band to argue there is a problem.
Tom's graph @ 126 very clearly showed the actual trend line that should be compared to the min/max trend lines. The actual trend line is about half way between the mean trend and the minimum trend. It is well within the range. QED.
If you disagree, then how would any of you determine that the models are inaccurate? What is your method of testing and validation?
Look at the second figure in the OP — Tamino's graph of projection trends and observation trends, together with their uncertainties.
If they were disjoint — i.e. if the projected trends with their ranges did not overlap meaningfully with the observed trends plus their uncertainties, then we'd want to go back and figure out what we missed (or whether, instead, we had miscalculated something).
We're a long way from that.
BTW, as has already been pointed out, HADCRUT4 has a known systematic error because it omits the fastest-warming regions of the globe. The models have no such error in their temperature calculations. If you're getting close to showing there could be a problem (which you aren't, but at some point it's possible) then it's worth checking to see whether it's what you're using for observations that are the cause, rather than the models. (This has happened before, with UAH, for example.) Alternatively, you could apply HADCRUT4's algorithm to the model output to compare like-with-like.
If your position is robust then it should stand up when using multiple data sets, not just the one data set that is known to underestimate warming. In other words, when you're right on the margin, you don't want to be accussed of cherry-picking the data set to prove your point.
In this case, however, we're not right on the margin, but it's good to be prepared should we eventually be so.
I’ve done a little more research, and I’ve stumbled upon something from the Met Office. This clears up some of the discussion, perhaps, and it is against some of the points I have made, so please give me credit for being honest and forthcoming in the discussion:
“We should not confuse climate prediction with climate change projection. Climate prediction is about saying what the state of the climate will be in the next few years, and it depends absolutely on knowing what the state of the climate is today. And that requires a vast number of high quality observations, of the atmosphere and especially of the ocean.”
“The IPCC model simulations are projections and not predictions; in other words the models do not start from the state of the climate system today or even 10 years ago. There is no mileage in a story about models being ‘flawed’ because they did not predict the pause; it’s merely a misunderstanding of the science and the difference between a prediction and a projection.”
I think this clears up some of the discussion, I think. Perhaps this is what some of you were trying to explain, but it didn’t come across very clear. I was thinking that GCMs are making predictions instead of projections. Nevertheless, I don’t like projections because they are not falsifiable. Without known inputs and projected outputs, and truth data to compare against, how are these models tested and validated? I can’t think of a single way to verify them, and only one way to falsify them, and that is for the climate to cool when it is projected to warm. So, if the current global temperature pause extends out further or turns into cooling, only then will we have a falsification of the models.
And here a few select replies to some points made above:
Tom Dayton @144: I’ll re-read the SkS post on “How Reliable are the Models” again. I had some specific issues with it, but I’ll keep them to that post. As for Steve Easterbrook’s explaination… did you read it and understand it? I don’t think so. One sentence there sums it all up: “This layered approach does not attempt to quantify model validity”. Nuf’said.
Leto @145: As for my username and background -- I am not pulling rank or appealing to authority as I understand those logical fallacies. I chose this name because it is what I do, and I think I know what I’m talking about when it comes to software and modeling. This doesn’t mean all modeling and all software, but it is easier for me to extrapolate my knowledge and experience from my domain than, say, someone in the mortuary business.
KR @146: yes, you are correct in that I was misunderstanding boundary and initial value problems. I’ve read up on them a little, and I am not sure how useful they in the longer term. In your traffic projection example, yes they work well, but only when all of your underlying assumptions are met. For example, 10 years ago Detroit assumed much about the economy and economic growth and built a lot of stuff. Then the broader economy turned down, people left, and the city has gone bankrupt. The future is really hard to predict.
I think models are at the very low end of their boundary conditions with the current pause. Whether all the heat is stealthily sinking into the deep ocean is a separate issue, but the fact remains that sea surface temps and global air temps have been very steady for a long time, contrary to the models projections. Even all the big climate houses are admitting the pause, so you guys might as well admit it too.
And for your statement of “as we have a pretty good handle on the physics”, I disagree. Sure we have a good understanding of a lot of physics, but in a chaotic and non linear system like the climate, I think there is much that is not known. Take ENSO, PDO, and ADO, no one has a good physics model describing these, and they are major drivers of the climate. Unless you believe there is almost nothing unknown in the climate, then your statement on having a good handle in physics is a red herring. Donald Rumsfeld said it best: “There are known knowns; there are things we know that we know. There are known unknowns; that is to say, there are things that we now know we don't know. But there are also unknown unknowns – there are things we do not know we don't know.” I am pretty confident that there will be some unknown unknowns that will turn current climate science on its head -- and the pause is starting to back it up. If Wyatt’s and Curry’s peer reviewed paper on “Stadium Waves” (see: http://www.news.gatech.edu/2013/10/10/%E2%80%98stadium-waves%E2%80%99-could-explain-lull-global-warming) published in Climate Dynamics is correct, the pause could last much longer and would clearly falsify the climate models and most of AGW. I think we have time to wait another decade or two before taking an drastic action on curbing CO2 emissions to see if the IPCC’s projections are correct or not.
Barry @149: coin flipping is a false analogy and not applicable forecasting climate or any chaotic system.
JasonB @150 (and Leto @145): As a decent poker player myself, it is not a foregone conclusion that an expert will beat a complete novice. On average it is much more likely an expert will win, but in any given instance the claim is not true at all. The entire casino industry is built upon the Central Limit Theorem, which states “the arithmetic mean of a sufficiently large number of iterates of independent random variables, each with a well-defined expected value and well-defined variance, will be approximately normally distributed.” If a roulette wheel pays 36-to-1 on selecting the correct number on the wheel but there are 38 numbers (counting 0 and 00), assuming a fair wheel that is random, then the house has a 5.3% advantage over the player. In the long run, they $0.053 for every dollar bet on the wheel. This gaming theory with a well defined mean does not apply to the climate – the climate is chaotic, non linear and does not have a well defined mean.
SAM @152, I have to disagree with you on the falsifiability of models based on projections based on two points:
1) Although models can only make projections of future climate changes, they can be run with historical forcings to make retrodictions of past climate changes. Because the historical forcings are not the quantities being retrodicted, this represents a true test of the validity of the models. This has been extended to testing whether models reproduce reconstructed past climates (including transitions between glacials and interglacials) with appropriate changes in forcings.
2) Even projections are falifiable. To do so simply requires that the evolution of forcings over a given period be sufficiently close to match those of a model projection; and that the temperatures in the period of the projection run consistently outside the outer bounds of the projected temperature range. It should be noted that, because the outer bounds are large relative to the projected change in temperature in the short term, that is almost impossible in the short term. In the longer term (30+ years), however, the projected (and possible) temperature changes are large relative to the outer bounds and falsification becomes easy. In other words, the experiment takes a long time to run. There is nothing wrong with that. It is simply the case that some experiments do take a long time to run. That does not make them any less scientific.
Stealth - Boundary value solutions can indeed deal with changes in forcings that were not in the original projection scenarios, by simply running on actual values. If the LA (or Detroit) freeway model accurately reflected those boundaries and limits, running it with a different set of economics would indeed give the average traffic for that scenario. That is the essence of running multiple projections with different emissions scenarios (RCPs) - projecting what might happen over a range of economic scenarios in order to understand the consequences of different actions.
And a projection is indeed testable - as Tom Curtis points out simply running a physically based boundary value model on past forcings should (if correct) reproduce historic temperatures, or perhaps using hold-out cross validation. And models can (and will) be tested against future developments, see the discussion of Hansens 1988 model and actual (as opposed to projected) emissions.
Finally, as to your statement "...in a chaotic and non linear system like the climate", I would have to completely disagree. Yes, there are aspects of chaos and non-linearity in the weather. But (and this is very important) even the most chaotic system orbits on an attractor, which center the long term averages, the climate. And the location of that attractor is driven by the boundary conditions, by thermodynamics and conservation of energy. Weather will vary around the boundary conditions, but the further it goes from balance the strong the correcting forcing.
Claiming that we cannot understand how the climate behaves under forcing changes is really an Appeal to Complexity fallacy - given that our models actually do very well.
Hmm, weather is chaotic. Whether climate is chaotic is an open question. Heat a large pan of water. The convection currents and surface temperatures are a challenge to model, but one thing for sure - while the heat at bottom exceeds heat loss from pan, then pan will keep on heating.
By the way, if you want to discuss modelling directly with the climate modellers then ask away at RealClimate (read their FAQ first) - or on Isaacc Held's blog when the US government reopens.
Stealth - "...the fact remains that sea surface temps and global air temps have been very steady for a long time, contrary to the models projections."
Did you actually read the opening post??? It doesn't appear so... See the third figure; recent (and by that I mean the 15-17 years discussed by deniers) trends are but short term, statistically insignificant noise, cherry-picked from an extreme El Nino to a series of La Ninas. It's noteworthy that similar length trends (1992-2006) can be shown to have trends just as extreme in the other direction - a clear sign that you are not looking at enough data.
I've said this before, discussing recent trends and statistically significant trends. Examining any time-span starting in the instrumental record and ending in the present:
Stealth wrote:
I am afraid you appear determined to resist enlightenment. Try to understand the conceptual point behind the analogies, rather than getting side-tracked into a discussion of the analogy itself. The odds of my mother beating the world expert in poker over several hours of play are close to zero, despite the unpredictable short-term possibility of her getting an unbeatable hand at any one moment, but that is not the point. The point is, the long-term predictability of an expert-vs-novice poker session is obviously much higher than its short-term predictability. The long-term rise in a swimming pool's level during filling is much more predictable than the moment-to-moment splashes. The physics of heat accumulation on the planet are much more amenable to modelling than short-term cycles and weather.
Don't argue the analogies unless you put the effort into understanding the concept behind them. The analogies were raised because you seemed to take it as axiomatic that long-term predictability could never exceed short-term predictability, a view that is trivially easy to falsify.
I think you have amply demonstrated that your experience in the aviation domain is actually preventing you from understanding. I see too much extrapolation from an entirely unrelated domain, which has a different dependence on small-scale and short-term phenomena completely unlike climatology, coupled with preconceived ideas about what conclusions you want to reach.
See above. The problem is with the receiver. The points were very clear to anyone prepared to be educated.
"have to respectfully disagree with you about testing climate model on past data. First, we really do not have enough solid and reliable measurements of the past to really determine the various components of the climate. "
Excuse me but have you read any paper on the topic at all? Looked at the paleoclimate section of WG1? You have measurements of various climatic parameters with obviously error bounds on them. You have have estimates of forcings with similar error bounds. You run the models and see whether range of results for forcings are within the error limits for forcings. Are the forcings well enough known to constrain the models for testing? Well no, in some cases, yes in others. You can certainly make the statement that observations of past climates are expliciable from modern climate theory.
Start at Chap 6 AR4. Read the papers.
(Rob P) - Please note that Stealth's last few comments have been deleted due to violation of the comments policy. Replies to these deleted comments have likewise been erased.
If you wish to continue, limit yourselves to either one or two commenters - in order to avoid 'dogpiling' on Stealth. And request that Stealth provide peer-reviewed literature to support his claims. Claims made without the backing of the peer-reviewed scientfic literature are nothing more than non-expert personal opinion.
Further 'dogpiling' and/or scientifically unsupported claims will result in comments being deleted.
Further to my graph @126, here is a similar graph for CMIP5:
The most important difference is that I have shown trends from 1983, to match the chart shown by Roy Spencer in a recent blog.
There are some important differences between my chart, and that by Spencer. First, I have used the full ensemble for RCP 8.5 (80 realizations, including multiple realizations from some individual models); whereas Spencer has used 90 realizations with just one realization per model, but not all realizations from the same scenario. Second, I have used thirty years of annual average data. Spencer has used the five year running, terminal mean. That is, his data for 1983 is the mean of the values from 1979-1983, and so on.
Even with these differences, the results are very similar (unsurprisingly). Specifically, where he has the percentile rank of the HadCRUT4 trend vs the Ensemble as less than 3.3% of the ensemble realizations, I have it at 3.43 %ile of the ensemble realizations. For UAH, the 30 year trend is at the 3.32 %ile of ensemble realizations. Taking trends from 1979 for a more direct comparison, then we have:
UAH: 2.29 [0, 32.2] %ile
HadCRUT4: 3.34% [0.96, 23.16] %ile
GISS: 3.45 [0.92, 28.66] %ile.
For those unfamiliar with the convention, the numbers in the square brackets are the upper and lower confidence bounds of the observed trends.
Mention of confidence intervals raises interesting points. Despite all Spencer's song and dance, the 30 year trends for HadCRUT4 and UAH do not fall outside the 2.5 to 97.5 %ile range, ie, the confidence intervals as defined by the ensemble. More importantly, the confidence intervals of the observed trends encompas have upper bounds in the second quartile of ensemble trends. Consequently, observations do not falsify the models.
This is especially the case as there are known biases on the observed trends which Spencer knows about, but chooses not to mention. The first of these is the reduced coverage of HadCRUT4, which give is a cool bias relative to truly global surface temperature measures. The second is the ENSO record (see inset), which takes us from the strongest El Nino in the SOI record (which dates back to 1873) to the strongest La Nino in the SOI record. This strong cooling trend in the physical world is not reflected in the models, which may show ENSO fluctations, but do not coordinate those fluctuations with the observed record.
Indeed, not only does Spencer not mention the relevance of ENSO, he ensured that his average taken from 1979 included the 1983, ei, the record El Nino, thereby ensuring that his effective baseline introduced a bias between models and observations. Unsurprisingly (inevitably from past experience), it is a bias which lowers the observed data relative to the model data, ie, it makes the observations look cooler than they in fact were.
Tom Curtis @159: Thanks for the quality posts. If we’re ever in the same town I’d like to buy you a beer or three. I might disagree with you on a few things, but I do appreciate your cogent and respectful posts.
You have drawn another nice chart. I think all of the charts discussed, including your current one, the one I’ve drawn @117, the one drawn by Spencer (http://www.drroyspencer.com/2013/10/maybe-that-ipcc-95-certainty-was-correct-after-all/), McIntyre’s (http://climateaudit.org/2013/10/08/fixing-the-facts-2/) and the two at the top of this page are all basically the same. They show model projections and the temperature data. Dana asserts that IPCC AR5 Figure 1.4 draft (his left chart at the top) was a mistake or has errors, but is now clear to me that it does not have any errors. The draft version (Dana’s left chart) from the IPCC matches the final draft version (Dana’s right chart), it’s just that the IPCC’s final version is zoomed out and harder to see.
This thread has discussed that initial conditions and boundary conditions are important, and using trend lines is important, but I disagree. Plotting model projection lines along with temperature data (not trend lines) much the way I have done, Spencer has done, McIntyre has done, is completely reasonable and meaningful. After all, this is the way the IPCC has drawn the chart in its final draft version (Dana’s right chart).
No matter how you slice it, the global temperature data is running at the very bottom of model projections. I think that falsification of model projections is near. If it temperature continues not warm for another 15 years as theorized by Wyatt’s and Curry’s Stadium Wave paper (http://www.news.gatech.edu/2013/10/10/%E2%80%98stadium-waves%E2%80%99-could-explain-lull-global-warming) then it will be obvious that climate models are inaccurate and falsified.
SASM wrote "inaccurate and falsified"
As GEP Box (who knew a thing or to about models, to say the least) said "all models are wrong, but some are useful". We all know the models are wrong, just look at their projections of Arctic sea ice extent. The fact they get that obviously wrong doesn't mean that the models are not useful, even though they are wrong (as all models are). Of course the reason skeptics don't latch on to this is because it is an area where the models underpredict the warming, so they don't want to draw attention to that.
It seems to me that SASM could do with re-evaluating his/her skepticism, and perhaps ask why it is he/she is drawing attention to the fact that the observations are running close to the bottom of model projections now, but appears to have missed the fact that they exceeded the top of model projections in 1983 (see Toms nice diagram). Did that mean the models were falsified in that year and proven to be under-predicting global warming? Please, lets have some consistency! ;o)
Tom, and others familiar with the data:
Is it possible to take the model ensemble and purge all those runs that are clearly ENSO-incompatible with the real-world sequence of el ninos and la ninas? (Obviously this begs the question of what counts as incompatible, but reasonable definitions could be devised.) In other words, do the runs have easily extractable SOI-vs-time data?
SASM @160, I have to disagree with your claim that the charts discussed "are all basically the same". For a start, your chart, Spencer's chart, and the 2nd order draft chart from the IPCC all use single years, or very short periods to baseline observations relative to the model ensemble mean. In your, and Spencer's case, you baseline of a five year moving average, effectively making the baseline 1988-1992 (you) or 1979-1983 (Spencer). The 2nd Order draft, of course, baselines the observations to models of the single year of 1990.
The first, and most important, problem with such short period baselines is that they are eratic. If a 1979-1983 base line is acceptable, then a 1985-1989 base line should be equally acceptable. The later baseline, however, raises the observations relative to the ensemble mean by 0.11 C, or from the 1.5th to the 2.5th percentile. Should considerations of whether a model has been falsified or not depend on such erratic baselining decisions?
Use of a single year baseline means offsets can vary by 0.25 C over just a few years (CMIP3 comparison), while with the five year mean it can vary by 0.15 C (CMIP5 comparison). That is, choice of baselining interval with short baselines can make a difference equal to or greater than the projected decadal warming in the relative positions of observations to model ensemble. When you are only comparing trends or envelope over a decade or two, that is a large difference. It means the conclusion as to whether a model is falsified or not comes down largely to your choice of baseline, ie, a matter of convention.
Given this, the only acceptable baselines are ones encompensing multiple decades. Ideally that would be a thirty year period (or more), but the 1980-1999 baseline is certainly acceptable, and necessary if you wish to compare to satellite data.
Spencer's graph is worse than the others in this regard. It picks out as its baseline period the five year interval which generates the largest negative offset of the observations at the start of his interval of interest (1979-2012); and the third largest in the entire interval. Given the frequency with which his charts have this feature, it is as if he were intentionally biasing the display of data. In contrast, the 1990 baseline used by you (as the central value in a five year average) and the 2nd Order draft generates a postive offset relative to the 1961-1990 baseline, and near zero offset relative to the 1980-1999 baseline. Although 1990 is a locally high year in the observational record, it is not as high relative to the ensemble mean as its neighbours. Consequently the 2nd Order draft generates a more favourable comparison then the longer baselines. It is an error, never-the-less, because that is just happenstance.
More later.
Regarding Spencer's chart, here are the HadCRUT4 (red) and UAH 5-year means - baselined to 1980-1999 (green) and Spencer and Christy's 1979-1983 extrema value (blue):
[Source]
Note how the Spencer and Cristy running mean UAH temps remain entirely below HadCRUT4 for the entire period - a clear sign of incorrect baselining, as they do not have common grounds from which to judge departures.
Dikran @161: I frequently use the quote, “all models are wrong, but some are more useful than others.” I have never said that climate models are not useful, only that we should not rely upon model projections as a basis of making policy decisions. They have not passed enough testing and verification for them to have that kind of power.
[text deleted here - reply to deleted comment (dogpiling)]
Tom Curits @164: I understand your position fully. I hate that you took so much time building charts to prove it. There are always problems on selecting the origin. I wasn’t trying to rig the chart to push the ensemble to the high side; I just used the starting date in the draft IPCC chart. I admit that 1990 +/- was a little bit of a warm year. So, let’s just focus on your chart @ 159. Can you compute the trend lines for the four anomaly curves without forcing all the lines to a common origin? In other words, compute the best fit line from 1983 to 2015 for each of the anomalies, or post the spreadsheet data somewhere and I’ll do it. The start point for each trend line should be on a vertical line at 1983. If you want to pick a different starting year that is fine too.
[JH] You have made your points ad naseum and are now skating on the thin ice of excessive repetition. Please cease and desist or face the consequences.
[Rob P] Text removed from comment for the reason outlined above.
SASM wrote "only that we should not rely upon model projections as a basis of making policy decisions."
O.K., so if we are not going to use models that embody what we know of climate physics, specifically what should we use as the basis for policy decisions?
"They have not passed enough testing and verification for them to have that kind of power."
Please specify how much testing and verification would be required for you to accept their use as a basis for policy making.
Lastly, please explain why you have not mentioned the occasions where models have under-predicted the effects of climate change.
SASM @165, unfortunately, I do not think you understand my position. In particular, I was not criticizing your choice of baseline on the basis that it makes the observations look cool. On the contrary, a 1990 baseline makes the observations look warm. The emphasis on that point is so that my allies pick up on the fact. Intuitively, we would expect a 1990 baseline to cause the observations to look cool, for 1990 is a local high point in the observations. However, that is not the case, for though the observations are warm, the ensemble mean is warmer still relative to adjacent years. Thus, if anything, a 1990 baseline is favourable to a defence of the validity of models.
But it is still wrong.
It is wrong, basically, because you have to analyze the data as you motivated me to do to know whether it is favourable, unfavourable or neutral with regard to any position. The only way to avoid that necessity is to use a long (thirty year) baseline so that the baseline is robust with respect to time period used. Ideally, we should use the long baseline that minimizes the Root Mean Squared Error (RMSE) between the observation and the ensemble mean. By doing so, we ensure that any discrepancy between observations and ensemble are real, ie, are not artifacts of an ill chosen baseline.
The impact of short baselines is shown by KR's graph @164. The UAH temperature record is far more sensitive to ENSO fluctations than any surface record. As a result, the inclusion of the strong El Nino of 1983 in a short baseline period artificially displaces the UAH record downwards with respect to HadCRUT4 (and both HadCRUT4 and UAH downward with respect to the ensemble mean).
The crux is this: Spencer (and you and McIntyre) have created graphs to illustrate the relationship between observations and models. Yet all of you have adopted non-standard conventions, the effect of which is to show a greater disparity than actually exists. This is achieved by three different methods in the three cases (and I have only discussed Spencer's method so far), but is the case none-the-less. Now, to the extent that you intend an honest comparison, you would avoid any method that might accidentally result in showing a greater disparity (if that is what you are trying to demonstrate). Short term baselining is a method that will have that effect. When it is adopted to compare data with known large differences in variance (as, for example, HadCRUT4 and UAH) it is scientific malpractice. It is, not to put to fine a point on it, the sort of thing I would expect from a person who uses a known faked Time magazine cover to establish a rhetorical point, and who refuses to take it down, issue a correction or acknowledge the fault when corrected by others.
I expect better of you than of Spencer. I expect you to at least acknowledge that the use of short baselines is bad practise, and should not be done for purposes of illustration nor in attempting to establish whether or not the observations have fallen outside the predicted range.
Leto @162, I am not sure that that can usefully be done. However, Kosaka and Xie have gone one better. They took a model, constrained the tropical pacific temperature values to historical values to force it to adopt the historical ENSO record, and compared that to observations:
Tamino's discussion (from which I draw the graph) is very informative.
To bring that back to the discussion on hand, I checked the 1990-2012 temperature trend of that model when run with the CMIP3 experiment. It was 0.317 C/decade. That puts it at the 80.8th percentile, and definitely one of the fastest warming models. Yet when constrained to historical ENSO fluctuations, it almost exactly matches the HadCRUT4 record.
This, I think, illustrates the absurdity of SASM's approach of testing models against just one value, and if they almost (but not quite) fail the test, rejecting them as completely irrelevant as a basis of information.
Thanks Tom@168.
I was aware of Kosaka and Xie. Their approach is interesting, but potentially open to the charge (by motivated parties) that the close match they demonstrated merely reflects that the model was constrained by reality, and hence matched reality. (The model was not actually tightly constrained, but we all know contrarians have run with weaker material.)
I was hoping that a few unconstrained model runs had chanced upon an ENSO profile similar to reality. For instance, if all model runs in the ensemble were ranked according to their mean squared SOI error with respect to the historical SOI, I would expect that the best-matched quartile (top 25% of runs in the ranking) would match reality more closely than other quartiles. After all, the models' developers never claimed to be able to predict ENSO conditions, so it would be nice to minimise the effects of ENSO mismatch. This would support the notion that the minor, statistically insignificant divergence between the ensemble mean and observational record (over some timeframes) is largely due to an el nino in 1998 followed by la nina and neutral conditions for many of the following years. It is a shame if this type of data is not available in the public domain.
Of course, if the science were being conducted in an ideologically neutral environment, such an obvious issue would not draw so much attention in the first place, and I would not propose such an analysis. For me, the Nielsen-Gammon plot, mentioned in several threads here at SkS, says it all.
Tom Curtis @168: “this illustrates the absurdity of SASM's approach of testing models against just one value”, you know, I had this very thought last night, and I agree with you totally.
The model ensembles show air temperature, but as this site has pointed out (presumably correctly), on the order of 90% of the energy goes into the oceans. Due to this, air temperature is almost irrelevant to the system. So, what would be a meaningful and informative test of climate models? How far back to look and what to examine or measure?
I do not think the models can properly represent the various components of the earth’s energy budget, all of which combine to produce an average air temperature. Air temperature is what everyone worries about the most, but that is just 1/3000th of the heat capacity of the earth, by volume. Since air is mostly warmed indirectly, it is important to correctly model the things that heat the air. In order for me to have a sliver of confidence in a climate model, I’d want to see that a model can reasonably** project changes in the energy budget, say: air temp, sea temp, humidity, cloud cover, and precipitation. If you have opinions about other or different drivers, then I’d like to hear about them.
I think these are the major components to the energy budget, and I’m only looking for global averages. I am not expecting climate models to able to predict when it will rain at some location. If climate scientists and modelers have a good handle on climate physics, then they should be able to do a reasonable** job at projecting the annual global average of these values. Let’s start from 1950, which is where the IPCC says our AGW effects start. Can anyone plot the model average and +/- 2.5%ile bounds for these values along with actual measured data? Or, can someone point me to a paper to covering this? I’d be stunned if someone has not already done this analysis.
**reasonable: let’s define “reasonable” as getting the trend direction correct. If a model projects one of these components to go up over the last 63 years, but it goes down, then the model is wrong for that component. If the model is wrong on several components, then how can anyone conclude they are correctly modeling the climate?
I didn’t think 63 years – from 1950 until today – was short term at all. Perhaps it is, or we’re miscommunicating. I’d like to see model projections for air temp, sea temp, humidity, cloud cover, and precipitation, just as it has been shown for only air temperature. Take the IPCC’s chart, or better yet, Tom Curtis’ chart @159 and so me the model projections for air temp, sea temp, humidity, cloud cover, and precipitation. Is that an unreasonable request or do you think it will have meaningless implications?
[JH] Your requests for the forecasts of the indicators that you have listed should be directed to the organizations who actually develop and maintain the GCMs. Please let us know if you need contact information for these organizations.
SASM If there was a serious inconsistency between the models and observations since 1950 (!) the skeptics might just have pointed it out by now, for that matter the modellers themselves might just have noticed and done something about it. Where there actually is a serious inconsistency (e.g. Arctic sea ice), the modellers are generally very happy to discuss it, that is what they do for a living.
Please could you clarify your position by answering the questions I asked earlier (at least the first two).
SASM wrote "You guys see that?"
The human eye is very good at seeing spurious patterns in noisy data, which is why scientists use statistics, if only as a sanity check. There are plenty of articles on SkS that deal with "climastrology", I suggest you read some of them before continuing this line of reasoning, you will find it is nothing new and not well founded.
SASM @170, my post @169 ended with a very clear statement:
Absent such an acknowledgement by you, there is no point in pursuing more complex issues with regards to models than their ability to predict GMST. If you cannot bring yourself to acknowledge very basic standards of practise when it comes to testing predictions, complicating the topic, in addition to being off topic in this thread (IMO) will simply multiply the opportunity for evasion. Indeed, evasion appears to me to be the purpose of your post @170.
Consequently, absent a clear acknowledgement by you of the inappropriateness of short baselines in model/observation comparisons, or a clear and cogent defence of the practise despite the twin disadvantages of eraticness and overstating of differnces in behaviour based on differences in variability, there is no point if further pursuing this (or any) topic with you.
I ask that other posters likewise decline to participate in your distractions until we have a clear statement by you on this point.
[JH] You have read my mind. I encourage your fellow commenters to follow your recommendation.
SASM, per Tom Curtis's post nu. 177, I, too, am not pursuing other questionable statements you have made until such time as you have answered his, and other's, questions.
I’m trying to answer all the questions. I thought I had indirectly answered them but it appears not. So, here are explicit answers to questions in reverse order of posting.
Tom Curtis @177: Yes, I agree with your statement that short baselines are not fair in determining whether or not climate models fail or not. However, I do not think I was doing that. I only tried to reproduce the draft chart (left chart) with original source data, and I did that. You don’t think 1990 is a good start because that is only 23 years ago and we need at least 30 years. Okay, I can accept that. I’d reference Spencer’s chart here, but there is no need, other than to say “shame on him” for using a fake Time cover. You *can* expect more from me, I promise. But I do not like trend lines because if they are long then it takes a long time to detect a change. As an example, I could fit a line to the last 100 years of data, and even if temps plunged back down to -0.5C, it would take a long time for the trend line to change. Please give me the return courtesy of acknowledging that point.
Dikran @ 175: I read some links on SkS when I searched “climastrology” and none applied to my observation. I believe you mean Apophenia (http://en.wikipedia.org/wiki/Apophenia), which is seeing things in random data. I’m familiar with it -- children seeing animals in clouds is a classic example. Are you asserting that I am “seeing things” and that SOI oscillations are short term and there are no multi-decadal oscillations? Or that statistics has shown that what appears as a long term (100+ year) sine wave in the SOI really is not there? I’d like to see those results. Wyatt’s and Curry’s Stadium Wave paper (I’ve posted links or you can Google it) talks exactly to the issue that there *are* long oscillations in the AMO and PDO. How do climate models represent these major and oscillating climate drivers? My impression is that models assume ENSO, AMO, PDO average out to zero. Which could be an enormous source of error, and it wouldn’t show up in hindcasting, but it would show up when the large oscillation changes phase, like the last decade. In examining Tom’s SOI chart @159, it is clear that SOI peaked in 1983 and 1998, and since 1998 it has been plunging. And most of the SOI was pretty high from 1975 to early 2000, which is where all of the warming has occurred since 1950. Could be something, or it could be apophenia again.
Dikran @166: The specific questions you want answered:
“O.K., so if we are not going to use models that embody what we know of climate physics, specifically what should we use as the basis for policy decisions?” I believe we should use science, and models can be part of that. I build models and pilots literally risk their lives on them (humbling thought to me), but we test the crap out of them. I explain fully the uncertainties we know about and when and where things are not accurate.I am not confident at all that current climate models are accurate.
“Please specify how much testing and verification would be required for you to accept their use as a basis for policy making.” Wow, this is a hard question to answer. There is not a defined amount, but a range of testing. There is unit testing, and depending on the subsystem, it may get a lot more testing. Most tests are designed to confirm requirements are met, so those types of tests a well defined. The hard tests are to match modeling with measurements. This is where we go fly a test, measure a bunch of data, and then compare it to model predictions. Trying to figure out differences can be very hard. Is it the model, was it random noisy world effects, was the test instrumentation calibrated, and so on. Validation testing of a model is more of an evolving process based on the model than a check list. Validating climate models is hard because we cannot test against very accurate data sets for very long. Hindcasting isn’t accurate enough because the uncertainties of climate conditions are much larger than the CO2 signal.
“Lastly, please explain why you have not mentioned the occasions where models have under-predicted the effects of climate change.” I don’t think it matters -- wrong is wrong. Any model projection data in Tom’s chart prior to 1992 is a little suspect. I am certain that models did not correctly call the Mt Pinatubo eruption, so the projection dip in the early 1990’s has to have been a retro active adjustment to account for Mt Pinatubo. This is a completely reasonable thing to do, but has anything else been done to make the models look better in the past? That is the good thing about the recent model projections – they are well recorded in IPCC documentation and the Internet, so trying to move the goal post is very hard.
[Rob P] - a portion of this reply addressing a 'dogpiling' comment has been deleted
60 Year cycle in the SOI?
I think not:
SASM, you should know better than to assert the existance of such a cycle based on just one "cycle" length of data, as in the inset of my graph @159, particularly given that the full series was displayed @69 of this discussion. I note that even the appearance of a period in the data since 1975 comes almost entirely from the solid sequence of 5 El Nino's in succession in the early 1990's, and the concidence that over the last decade El Nino's (when occuring) have got successively weaker as the La Nina's have got successively stronger. There may possibly be reason for this as a response to forcing (although I know of no evidence to that effect). There is certainly no reason to think that these two occurences, without precedent in the rest of the record, consist of part of a cyclical pattern.
In my opinion, SASM's responses to my questions demonstrate that he has no substantive point to make and is essentially just trolling. His comments also show quite astonishing level of hubris and evidence of the Dunning-Kruger effect, so I susggest that we no longer indulge this sort of behaviour.
Question 1:
SASM wrote "only that we should not rely upon model projections as a basis of making policy decisions."
So I asked "O.K., so if we are not going to use models that embody what we know of climate physics, specifically what should we use as the basis for policy decisions?"
SASM replied "I believe we should use science, and models can be part of that. ..." This is an evasive answer, which basically is a tacit admission that SASM has no suggestion of any alternative to the models (which are essentially a distillation of what we know about the science. My question was designed to discover whether SASM actually had a substantive point to make, and it appears that he does not.
SASM continues "I build models and pilots literally risk their lives on them (humbling thought to me), but we test the crap out of them." This is an example of the hubris I mentioned, SASM assumes that the scientists have not "tested the crap out of them" and has not bothered to find out. The models are tested in what are called "model intercomparison projects", with acronyms that end in "MIP". There are dozens of them (of which CMIP3 and CMIP5 are merely the best known, there are also AOMIP, ARMIP, AMIP, TransCom, CCMLP, C20C, C4MIP, DYNAMO, EMDI, EMICs, ENSIP, GABLS, GCSS, GRIPS, GLACE, GSWP, MMII, OCMIP, OMIP, PMIP, PILPS, PIRCS, RMIP, SMIP-2, SMIP-2/HFP, SIMIP, SnowMIP, SWING, SGMIP, STOIC etc (see McGuffie and Henderson-Sellers, "A Climate Modelling Primer", Wiley, table 6.5 for more details). SASM is essentially indulging in boasting, suggesting that his field is superior to climate modelling, without actually bothering to find out what climate modelling involves. This is a classic symptom of Dunning-Kruger syndrome.
SASM continues "I explain fully the uncertainties we know about and when and where things are not accurate." Which is exactly what the climate modellers do, which is the point of running all the model intercomparison projects.
SASM continues "I am not confident at all that current climate models are accurate." but cannot suggest any other approach, which is the point. Sometimes decisions have to be made under uncertainty, and it would be irrational to ignore the best source of information we have on what is likely to ocurr in the future just because it isn't perfect. As I said, SASM has no substantive point to make.
Question 2
SASM wrote: "They have not passed enough testing and verification for them to have that kind of power."
So I asked "Please specify how much testing and verification would be required for you to accept their use as a basis for policy making."
SASM replied "Wow, this is a hard question to answer. There is not a defined amount, but a range of testing." Again, SASM ducked the question. The reason I asked the question was to see if there actually was some feasible test that would satisfy SASM's concern, or not. His answer strongly suggests that no amount of testing that could be performed would satisfy SASM and that in fact it is just a way of avoiding accepting what the models say, no matter what. In other words, just trolling with no scientific point to make.
SASM continues "There is unit testing, and depending on the subsystem, it may get a lot more testing. ... This is where we go fly a test, measure a bunch of data, and then compare it to model predictions." This is just more posturing and hubris. Climate modellers know about unit testing as well, and the also perform testing against observations, which is what all those MIPs are for.
SASM continues "Validating climate models is hard because we cannot test against very accurate data sets for very long. Hindcasting isn’t accurate enough because the uncertainties of climate conditions are much larger than the CO2 signal." Again, this is an indication that no test that could be performed will satisfy SASM, because the data will always not be accurate enough (for some unspecified reason). The second sentence is also an unsupported assertion, that is at odds with what we currently know about climate variability (this is another example of hubris).
Question 3
I asked “Lastly, please explain why you have not mentioned the occasions where models have under-predicted the effects of climate change.”
"I don’t think it matters -- wrong is wrong." Again an evasive answer. It actually matters quite a lot. If the models more frequently under-predicted the warming than over-predicted it, that would imply we should make greater efforts to mitigate against climate change. The fact that SASM is apparently only interested in where the model over-predicts in combination with his previous comment "The concern I have about all of this is how policy developers and those with an agenda try to take the model results and over inflate them in an attempt to redirect the economy. That is big money, and if we’re going to spend a large part of the world’s GDP, we’d better be very certain of the reason." suggests that science is being used here as a smokescreen for economics/politics. Evading the direct question is merely evidence to support this hypothesis.
SASM made things worse by writing "Any model projection data in Tom’s chart prior to 1992 is a little suspect. I am certain that models did not correctly call the Mt Pinatubo eruption, so the projection dip in the early 1990’s has to have been a retro active adjustment to account for Mt Pinatubo." This is astonishing hubris as it just shows that SASM has no real idea of how climate models work. Volcanic activity is a forcing, i.e. it is an input to the model. Observed forcings are used in making hindcasts, and the test is to see whether the model produces the correct response to the input. In fact models were used to predict the effects of Pinatubo in advance as a test of the models. It is ironic that you should be so certain of "retroactive adjustment", when you could easily have dound out with the slightest amount of checking your facts. Instead SASM chooses to make some thinly veiled slurrs "This is a completely reasonable thing to do, but has anything else been done to make the models look better in the past? That is the good thing about the recent model projections – they are well recorded in IPCC documentation and the Internet, so trying to move the goal post is very hard." implying that goal posts had been moved in the past.
On Apophenia
SASM wrote "Or that statistics has shown that what appears as a long term (100+ year) sine wave in the SOI really is not there?"
You have normal scientific process exactly reversed there. If someone wants to assert that there is a long term cycle there, the onus is on them to demonstrate that the observations are not explainable by random chance (under some suitable non-straw man null hypothesis). That is the way statistical hypothesis testing works. Of course occasionally papers get published (such as the Stadium Wave idea) and (while they may be interesting hypotheses) generally only use a straw man null-hypothesis, or don't actually perform a statistical test and generally have no plausible physical mechanism that can explain the size of the effect. The litterature is full of such papers, and so far they have generally led nowhere.
SASM wrote "My impression is that models assume ENSO, AMO, PDO average out to zero." Again, more hubris, that ENSO/AMO/PDO may average out to zero in the long term may be a valid conclusion to draw fromthe models, it certainly isn't an assumption built into them.
Dikran @178: I’m ignoring most of the accusations you make and all of your sidelobe jamming, except for the accusation of boasting, hubris, claiming my field is superior, and “not trying to find out what climate models involve”. Huh? That is exactly what I am trying to do on this site, but it has been circuitous due to (-snip-).
Geeze. I admit I have asked pointed questions, and part of this is to get you all to respond and defend the science. I am not exactly sure of what to look for, but your defense helps me figure out what I need to examine, and now I have a much better idea. Thanks!
Question 3: I retract my comment about being suspect about retro active adjustments to the models. It was late and I was tired. What I really meant to say is: clearly some sort of inputs are inserted into the model to properly force climate responses to volcanic eruptions. This is a completely reasonable thing to do, but my question is about other input adjustments that are injected into the models in the past to “get them to balance, or to reproduce observed results.” I am curious if (note, this word “if”, as in “maybe”) there are any of those types of input adjustments, and if so, what are they and why are they done.
I think this thread is winding down for me. I doubt anyone here can answer the questions I now have because you do not know enough about how the models are built. If I’m wrong and you do know a lot about how the models are built, I’d love to talk to on the side and offline. I have given more thought about how to test climate models, and the best would be to make projections and measure the results against real world measurements. Unfortunately, the issue with this is the amount of time it takes. Currently, I think a subsystem analysis of the various components of the model is the best that can be done. I would like to see what GCMs predict/forecast/project for major climatic components, not just air temperature. Here is a summary of what I am looking for:
I am looking for the forcing input adjustments used to represent volcanic and other random forcing. I would like to see model global projections (mean, 97.5%ile and 2.5%ile) from 1950 for air temp for multiple altitude layers, sea temp for multiple depth layers, humidity or water vapor by altitude layer, global cloud cover, and precipitation. I would also like actual measurements of these values.
Moderator JH @ 171: If you have any contact information for the organizations that develop and maintain the GCMs, I would like that. I assume you do not want to post their email and/or phone numbers. You can email the information to my email that I used to sign up on this website (it is a real email address, and please keep it private).
[PW] Accustations of impropriety removed. Your further reluctance to answer direct questions also noted.
SASM - As pointed earlier, some/lot of this is in FAQ on climate modelling at Realclimate (where you can ask the GISS modellers).
FAQ- 1 and FAQ - 2
I am a little puzzled about what you mean about "inputs inserted in models for volcanic forcings". The big point about Pinatuba, was models forecast what an eruption like that would do (Hansen at al 1992) and then after the eruption (put in actual forcing), confirm the result (Hansen et al 1996). The only thing you "add" to model is the actual forcing in terms of aerosol load. The response to the forcing was already in the model. So models say "If you get X aerosol loading, then you should get Y responses". When X actually happens, you put in actual loading and compare output with observations. I dont think models have "random" forcings. In running a projection for next 100 years, you have to put in "random" volcanoes" at the rate you expect to get eruptions to happen historically otherwise model runs too warm. Noone expects that eruptions will actually happen at those dates, but if eruption rate matches historical norm, then 30 year trends should be predicted. Is that what you mean?
If you are putting a lot of thought into evaluating of climate models, then I hope you are also putting a lot of reading into Chp 9 of AR5 which precisely about this. if you want to know about models are made, then why not read the primary literature first instead of speculating?
Scaddenp @180: Thanks for the links. I’m downing loading AR5 Chp 9 now for a trip tomorrow. I have about 6 hours of captive time for a bit of reading. Ugh, 207 pages, but I’m sure it will be easy reading [sarc].
What I mean by “inputs for volcanic climate forcing” is: If in 1990 for the FAR they run a GCM from 1990 until 2090, then the models would not properly project the large temperature drop around 1992. How could it, no one knew that Mt. Pinatubo would erupt before it happened. Then, for the SAR report in 1995 and after Mt Pinatubo, the models are run again from 1990 until 2090, but this time they have “injected” additional data into the model with estimates of aerosols from Mt Pinatubo. This, of course, causes sunlight to reflect and the temperature takes a big dive. The models show this effect, so assuming the physics haven’t changed from 1990 to 1995, then there has to be a way to tell the model about a specific large eruption. Without that additional input data, I would think the model would produce the same result as in 1990, assuming the model is deterministic, which may not be the case. This is not a complaint, just an observation. Some of you are so jumpy and ready to pounce on me, that I’m starting to qualify a lot of what I say.
Moderator PW @179: So it is okay for Dikran to accuse me of Dunning Kruger syndrome, and state I haven’t bothered to find out about models – which is EXACTLY why I’m on this site. Then he states I think my field is better than climate modeling, when I’ve said no such thing at all! He can kick me all over, tell me to read up climatrology, which has nothing to do with anything in this thread and try to send me on wild goose chases. That isn’t obfuscation? C’mon.
BTW, what question have I failed to answer and is being noted and tracked? I apologize if I missed one, but trying to discuss things with an angry mob can be confusing.
[JH] You came to this website with a chip on your shoulder. If you lose that, people will respond to you with civility.
SASM @ 179:
I highly recommend that you do more homework about GCMs before you begin to correspond with various modeling groups.
In addition to reading Chapter 9 of ARM 5, you should careful go through the Climate Modeling 101 website created by the National Academy of Sciences. [Link fixed - I hope.]
http://www.nap.edu/catalog.php?record_id=13430
"There has to be a way of telling the model about..." well of couse there is. Forcings are input into the model. The CMIP experiment is about getting the different modelling communities to run the same forcing experiments and comparing results. The forcings to use are on the site but I see it is still down due the goverment shutdown.
John Hartz @184: Oh, I would. I wouldn’t do anything like contact GISS. Why would they waste their time talking to me? I understand that.
Your link to CM101 is broken, by the way, but I found it with Google. In looking at #2 “Understanding Computer Models” – I have some experience with every one listed, and enormous experience with some (i.e. flight simulators). The 101 video was extremely simple; I’m sure it is aimed at the masses, but remember I am a software modeler with a computer science and physic degree and 30+ years of experience. I’m looking for a lot more meat and the details. The devil is always in the details.
I’ve got Chapter 9 printed out. Hate that I nearly killed a tree, but I skipped all the references in the middle, and printed two pages per page, so that saved a bunch of paper.
[JH] The most prominent feature of the Climate Modeling 101 website is the National Acadamy of Scinces report,
I highly recommend that you study this report if you are sincere in your stated goal of better understanding how global climate models work.
Moderator JH @183: Okay, fair enough. I’ll take the blame for starting the pissing contest. I do want good communication. Honestly! It is very easy to miscommunicate in email and upset people, and that is when they know who you are. Blog posts greatly amplify this effect because people will shoot off because of the anonymity. But I’m sure I’m not telling you anything new as a moderator.
[JH} Been there. Done that. Let's all move forward in a civil manner.
"The devil is always in the details." Agreed - which are not going to get in blog comments. If you are ready for that, then you should be moving on the primary literature and WG1 works pretty well as an "index" to that.
SASM If you want to learn about models, then there are some very good books that are well worth reading on the subject. I have "A Climate Modelling Primer" by McGuffie and Henderson-Sellers, Wiley (there appears to be a new edition available shortly), which I would recommend. I would also recommend "Principles of Planetary Climate" by Raymond Pierrehumber (Cambridge University Press), although that is generally more concerned with basic physics and more basic models than GCMs. I have used GCMs for my research, and it took a lot of background reading before I had a good grasp of the essentials.
The IPCC have made all the data from the model runs publically available, including information about the forcings, so if you want to know how this is done, there is nothing to stop you from getting the data and finding out the answers to your questions. You appear to have a suitable background for this kind of work, but you just need to learn the basics of climate modelling first, before reaching judgements.
For SteathGuy, I would recommend looking at energy balance models first. Go over to this web site that generates model-based fits to various temperature series and intereract with the graphs:
http://entroplet.com/context_salt_model/navigate
I spend too much time at Curry's site tryin to reason with the skeptics and I at least give you credit for trying to construct a somewhat methodical argument. I just suggest that instead of looking at the GCMs at first, that you try to pull apart the possible independent factors that give rise to subdecadal and decadal climate variability. The snaphot below is a view of an interface that you can play with and see how the various lags have an effect on volcanic disturbances, TSI, etc.
WebHubTelescope @190, can you direct me to documentation justifying the SALT model method, because on a casual perusal I am far from impressed.
My initial concerns were raised by the tunable, and different lags for different forcings. If you allow yourself to tune lags, I am sure you can get some very good fits between models and observations, but a physical explanation as to why solar forcings should have half the lag of anthropogenic forcings, and nearly one sixth that of volcanic forcings is decidedly lacking.
On closer inspection, I am even more perplexed. The "fluctuation components" show a very large, unexplained "linear" adjustment peaking at 0.396 in Nov 1943, and apart for its rapid fall off, is essentially zero at all other times. That is by far the largest single fluctuation value on the chart, and has no apparent physical basis. The lod adjustment is also unexplained (what does lod stand for?) and is certainly not a component of the GISS model forcings. Further, the volcanic "fluctuation component" does not match the GISS model forcings from the 1920s to 1940s.
Without documentation, it appears from the "fluctuation components" chart that arbitrary "fluctuations" are added as necessary to ensure a fit between model and observations. If so, we should be less than impressed that a fit is then found.
Tom Curtis,
Healthy skepticism is warranted. I have more info here on the general approach:
http://contextearth.com/2013/10/04/climate-variability-and-inferring-global-warming/
The October 1943 spike is the single anthro effect I added apart from CO2. You can turn that off by checking off anthro aerosols. I added that because since the overall agreement is so good, one can really start to look at particular points in time for further evaluation.
All the lags can be modified by the user. You can turn all of them off by setting the lags to zero. The agreement is still good.
The application of the LOD (length of day) is crucial as a proxy for multidecadal oscillations. This ensures conservation of energy and conservation of momentum according to work by Dickey et al at NASA JPL [1]. The fluctuations in kinetic energy have to go somewhere and of course changes in temperature are one place for this dissipation.
As far as volcanic disturbances, I took the significant ones from the BEST spreadsheet of Muller. If you can point me to the volcanic fording data from GISS, I can use that instead. Thanks !
[1] J. O. Dickey, S. L. Marcus, and O. de Viron, “Air Temperature and Anthropogenic Forcing: Insights from the Solid Earth,” Journal of Climate, vol. 24, no. 2, pp. 569–574, 2011.